Java虚拟机是如何执行字节码指令的?
执行引擎是 Java 虚拟机最核心的组成部分之一。「虚拟机」是相对于「物理机」的概念,这两种机器都有代码执行的能力,区别是物理机的执行引擎是直接建立在处理器、硬件、指令集和操作系统层面上的,而虚拟机执行引擎是由自己实现的,因此可以自行制定指令集与执行引擎的结构体系,并且能够执行那些不被硬件直接支持的指令集格式。
在 Java 虚拟机规范中制定了虚拟机字节码执行引擎的概念模型,这个概念模型成为各种虚拟机执行引擎的统一外观(Facade)。在不同的虚拟机实现里,执行引擎在执行 Java 代码的时候可能会有解释执行(通过解释器执行)和编译执行(通过即时编译器产生本地代码执行)两种方式,也可能两者都有,甚至还可能会包含几个不同级别的编译器执行引擎。但从外观上来看,所有 Java 虚拟机的执行引擎是一致的:输入的是字节码文件,处理过程是字节码解析的等效过程,输出的是执行结果。
一. 运行时栈帧结构
二. 方法调用
方法调用并不等同于方法执行,方法调用阶段唯一的任务就是确定被调用方法的版本(即调用哪一个方法),暂时还不涉及方法内部的具体运行过程。
在程序运行时,进行方法调用是最为普遍、频繁的操作。前面说过 Class 文件的编译过程是不包含传统编译中的连接步骤的,一切方法调用在 Class 文件里面存储的都只是符号引用,而不是方法在运行时内存布局中的入口地址(相当于之前说的直接引用)。这个特性给 Java 带来了更强大的动态扩展能力,但也使得 Java 方法调用过程变得相对复杂起来,需要在类加载期间,甚至到运行期间才能确定目标方法的直接引用。
解析
所有方法调用中的目标方法在 Class 文件里都是一个常量池中的符号引用,在类加载的解析阶段,会将其中一部分符号引用转化为直接引用,这种解析能成立的前提是方法在程序真正运行之前就有一个可确定的调用版本,并且这个方法的调用版本在运行期是不可改变的。话句话说,调用目标在程序代码写好、编译器进行编译时就必须确定下来。这类方法的调用称为解析(Resolution)。
Java 语言中符合「编译器可知,运行期不可变」这个要求的方法,主要包括静态方法和私有方法两大类,前者与类型直接关联,后者在外部不可被访问,这两种方法各自的特点决定了它们都不可能通过继承或者别的方式重写其它版本,因此它们都适合在类加载阶段解析。
与之相应的是,在 Java 虚拟机里提供了 5 条方法调用字节码指令,分别是:
- invokestatic:调用静态方法;
- invokespecial:调用实例构造器 方法、私有方法和父类方法;
- invokevirtual:调用所有虚方法;
- invokeinterface:调用接口方法,会在运行时再确定一个实现此接口的对象;
- invokedynamic:先在运行时动态解析出调用点限定符所引用的方法,然后再执行该方法。
只要能被 invokestatic 和 invokespecial 指令调用的方法,都可以在解析阶段中确定唯一的调用版本,符合这个条件的有静态方法、私有方法、实例构造器、父类方法 4 类,它们在加载的时候就会把符号引用解析为直接引用。这些方法可以称为非虚方法,与之相反,其它方法称为虚方法(final 方法除外)。
Java 中的非虚方法除了使用 invokestatic、invokespecial 调用的方法之外还有一种,就是被 final 修饰的方法。虽然 final 方法是使用 invokevirtual 指令来调用的,但是由于它无法被覆盖,没有其它版本,所以也无需对方法接受者进行多态选择,又或者说多态选择的结果肯定是唯一的。在 Java 语言规范中明确说明了 final 方法是一种非虚方法。
解析调用一定是个静态过程,在编译期间就能完全确定,在类装载的解析阶段就会把涉及的符号引用全部转变为可确定的直接引用,不会延迟到运行期再去完成。而分派(Dispatch)调用则可能是静态的也可能是动态的,根据分派依据的宗量数可分为单分派和多分派。这两类分派方式的两两组合就构成了静态单分派、静态多分派、动态单分派、动态多分派 4 种分派组合情况,下面我们再看看虚拟机中的方法分派是如何进行的。
分派
面向对象有三个基本特征,封装、继承和多态。这里要说的分派将会揭示多态特征的一些最基本的体现,如「重载」和「重写」在 Java 虚拟机中是如何实现的?虚拟机是如何确定正确目标方法的?
静态分派
在开始介绍静态分派前我们先看一段代码。
/**
* 方法静态分派演示
*
* @author baronzhang
*/
public class StaticDispatch {
private static abstract class Human { }
private static class Man extends Human { }
private static class Woman extends Human { }
private void sayHello(Human guy) {
System.out.println("Hello, guy!");
}
private void sayHello(Man man) {
System.out.println("Hello, man!");
}
private void sayHello(Woman woman) {
System.out.println("Hello, woman!");
}
public static void main(String[] args) {
Human man = new Man();
Human woman = new Woman();
StaticDispatch dispatch = new StaticDispatch();
dispatch.sayHello(man);
dispatch.sayHello(woman);
}
}运行后这段程序的输出结果如下:
Hello, guy!
Hello, guy!稍有经验的 Java 程序员都能得出上述结论,但为什么我们传递给 sayHello() 方法的实际参数类型是 Man 和 Woman,虚拟机在执行程序时选择的却是 Human 的重载呢?要理解这个问题,我们先弄清两个概念。
Human man = new Man();上面这段代码中的「Human」称为变量的静态类型(Static Type),或者叫做外观类型(Apparent Type),后面的「Man」称为变量为实际类型(Actual Type),静态类型和实际类型在程序中都可以发生一些变化,区别是静态类型的变化仅发生在使用时,变量本身的静态类型不会被改变,并且最终的静态类型是在编译期可知的;而实际类型变化的结果在运行期才可确定,编译器在编译程序的时候并不知道一个对象的实际类型是什么。
弄清了这两个概念,再来看 StaticDispatch 类中 main() 方法里的两次 sayHello() 调用,在方法接受者已经确定是对象「dispatch」的前提下,使用哪个重载版本,就完全取决于传入参数的数量和数据类型。代码中定义了两个静态类型相同但是实际类型不同的变量,但是虚拟机(准确的说是编译器)在重载时是通过参数的静态类型而不是实际类型作为判定依据的。并且静态类型是编译期可知的,因此在编译阶段, Javac 编译器会根据参数的静态类型决定使用哪个重载版本,所以选择了 sayHello(Human) 作为调用目标,并把这个方法的符号引用写到 man() 方法里的两条 invokevirtual 指令的参数中。
所有依赖静态类型来定位方法执行版本的分派动作称为静态分派。静态分派的典型应用是方法重载。静态分派发生在编译阶段,因此确定静态分派的动作实际上不是由虚拟机来执行的。
另外,编译器虽然能确定方法的重载版本,但是很多情况下这个重载版本并不是「唯一」的,因此往往只能确定一个「更加合适」的版本。产生这种情况的主要原因是字面量不需要定义,所以字面量没有显示的静态类型,它的静态类型只能通过语言上的规则去理解和推断。下面的代码展示了什么叫「更加合适」的版本。
/**
* @author baronzhang
*/
public class Overlaod {
static void sayHello(Object arg) {
System.out.println("Hello, Object!");
}
static void sayHello(int arg) {
System.out.println("Hello, int!");
}
static void sayHello(long arg) {
System.out.println("Hello, long!");
}
static void sayHello(Character arg) {
System.out.println("Hello, Character!");
}
static void sayHello(char arg) {
System.out.println("Hello, char!");
}
static void sayHello(char... arg) {
System.out.println("Hello, char...!");
}
static void sayHello(Serializable arg) {
System.out.println("Hello, Serializable!");
}
public static void main(String[] args) {
sayHello('a');
}
}上面代码的运行结果为:
Hello, char!这很好理解,‘a’ 是一个 char 类型的数据,自然会寻找参数类型为 char 的重载方法,如果注释掉 sayHello(chat arg) 方法,那么输出结果将会变为:
Hello, int!这时发生了一次类型转换, ‘a’ 除了可以代表一个字符,还可以代表数字 97,因为字符 ‘a’ 的 Unicode 数值为十进制数字 97,因此参数类型为 int 的重载方法也是合适的。我们继续注释掉 sayHello(int arg) 方法,输出变为:
Hello, long!这时发生了两次类型转换,‘a’ 转型为整数 97 之后,进一步转型为长整型 97L,匹配了参数类型为 long 的重载方法。我们继续注释掉 sayHello(long arg) 方法,输出变为:
Hello, Character!这时发生了一次自动装箱, ‘a’ 被包装为它的封装类型 java.lang.Character,所以匹配到了类型为 Character 的重载方法,继续注释掉 sayHello(Character arg) 方法,输出变为:
Hello, Serializable!这里输出之所以为「Hello, Serializable!」,是因为 java.lang.Serializable 是 java.lang.Character 类实现的一个接口,当自动装箱后发现还是找不到装箱类,但是找到了装箱类实现了的接口类型,所以紧接着又发生了一次自动转换。char 可以转型为 int,但是 Character 是绝对不会转型为 Integer 的,他只能安全的转型为它实现的接口或父类。Character 还实现了另外一个接口 java.lang.Comparable,如果同时出现两个参数分别为 Serializable 和 Comparable 的重载方法,那它们在此时的优先级是一样的。编译器无法确定要自动转型为哪种类型,会提示类型模糊,拒绝编译。程序必须在调用时显示的指定字面量的静态类型,如:sayHello((Comparable) 'a'),才能编译通过。继续注释掉 sayHello(Serializable arg) 方法,输出变为:
Hello, Object!这时是 char 装箱后转型为父类了,如果有多个父类,那将在继承关系中从下往上开始搜索,越接近上层的优先级越低。即使方法调用的入参值为 null,这个规则依然适用。继续注释掉 sayHello(Serializable arg) 方法,输出变为:
Hello, char...!7 个重载方法以及被注释得只剩一个了,可见变长参数的重载优先级是最低的,这时字符 ‘a’ 被当成了一个数组元素。
前面介绍的这一系列过程演示了编译期间选择静态分派目标的过程,这个过程也是 Java 语言实现方法重载的本质。
动态分派
动态分派和多态性的另一个重要体现「重写(Override)」有着密切的关联,我们依旧通过代码来理解什么是动态分派。
/**
* 方法动态分派演示
*
* @author baronzhang
*/
public class DynamicDispatch {
static abstract class Human {
abstract void sayHello();
}
static class Man extends Human {
@Override
void sayHello() {
System.out.println("Man say hello!");
}
}
static class Woman extends Human {
@Override
void sayHello() {
System.out.println("Woman say hello!");
}
}
public static void main(String[] args){
Human man = new Man();
Human woman = new Woman();
man.sayHello();
woman.sayHello();
man = new Woman();
man.sayHello();
}
}代码执行结果:
Man say hello!
Woman say hello!
Woman say hello!对于上面的代码,虚拟机是如何确定要调用哪个方法的呢?显然这里不再通过静态类型来决定了,因为静态类型同样都是 Human 的两个变量 man 和 woman 在调用 sayHello() 方法时执行了不同的行为,并且变量 man 在两次调用中执行了不同的方法。导致这个结果的原因是因为它们的实际类型不同。对于虚拟机是如何通过实际类型来分派方法执行版本的,这里我们就不做介绍了,有兴趣的可以去看看原著。
我们把这种在运行期根据实际类型来确定方法执行版本的分派称为动态分派。
单分派和多分派
方法的接收者和方法的参数统称为方法的宗量,这个定义最早来源于《Java 与模式》一书。根据分派基于多少宗量,可将分派划分为单分派和多分派。
单分派是根据一个宗量来确定方法的执行版本;多分派则是根据多余一个宗量来确定方法的执行版本。
我们依旧通过代码来理解(代码以著名的 3Q 大战作为背景):
/**
* 单分派、多分派演示
*
* @author baronzhang
*/
public class Dispatch {
static class QQ { }
static class QiHu360 { }
static class Father {
public void hardChoice(QQ qq) {
System.out.println("Father choice QQ!");
}
public void hardChoice(QiHu360 qiHu360) {
System.out.println("Father choice 360!");
}
}
static class Son extends Father {
@Override
public void hardChoice(QQ qq) {
System.out.println("Son choice QQ!");
}
@Override
public void hardChoice(QiHu360 qiHu360) {
System.out.println("Son choice 360!");
}
}
public static void main(String[] args) {
Father father = new Father();
Father son = new Son();
father.hardChoice(new QQ());
son.hardChoice(new QiHu360());
}
}代码输出结果:
Father choice QQ!
Son choice 360!我们先来看看编译阶段编译器的选择过程,也就是静态分派过程。这个时候选择目标方法的依据有两点:一是静态类型是 Father 还是 Son;二是方法入参是 QQ 还是 QiHu360。因为是根据两个宗量进行选择的,所以 Java 语言的静态分派属于多分派。
再看看运行阶段虚拟机的选择过程,也就是动态分派的过程。在执行 son.hardChoice(new QiHu360()) 时,由于编译期已经确定目标方法的签名必须为 hardChoice(QiHu360),这时参数的静态类型、实际类型都不会对方法的选择造成任何影响,唯一可以影响虚拟机选择的因数只有此方法的接收者的实际类型是 Father 还是 Son。因为只有一个宗量作为选择依据,所以 Java 语言的动态分派属于单分派。
综上所述,Java 语言是一门静态多分派、动态单分派的语言。
三. 基于栈的字节码解释执行引擎
虚拟机如何调用方法已经介绍完了,下面我们来看看虚拟机是如何执行方法中的字节码指令的。
解释执行
Java 语言常被人们定义成「解释执行」的语言,但随着 JIT 以及可直接将 Java 代码编译成本地代码的编译器的出现,这种说法就不对了。只有确定了谈论对象是某种具体的 Java 实现版本和执行引擎运行模式时,谈解释执行还是编译执行才会比较确切。
无论是解释执行还是编译执行,无论是物理机还是虚拟机,对于应用程序,机器都不可能像人一样阅读、理解,然后获得执行能力。大部分的程序代码到物理机的目标代码或者虚拟机执行的指令之前,都需要经过下图中的各个步骤。下图中最下面的那条分支,就是传统编译原理中程序代码到目标机器代码的生成过程;中间那条分支,则是解释执行的过程。
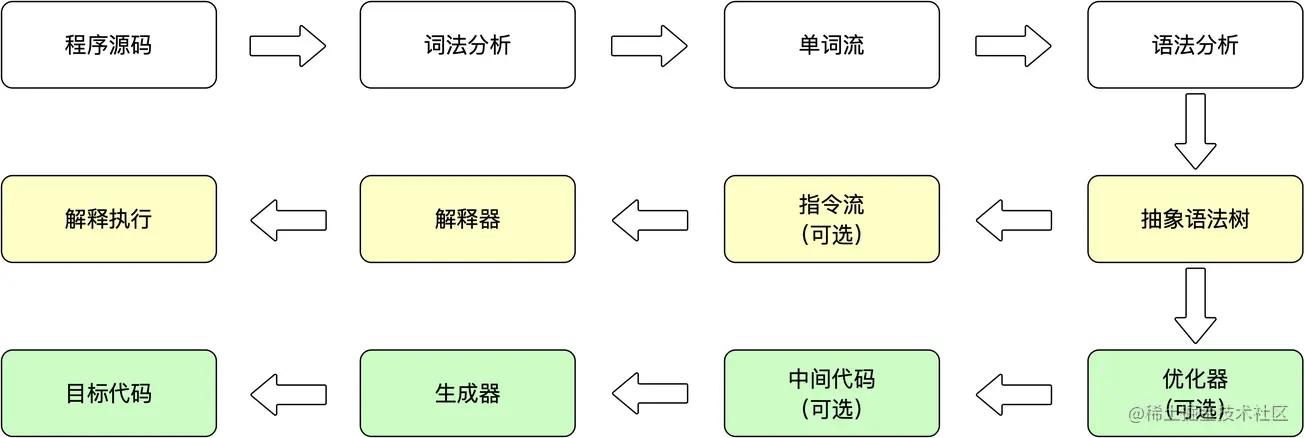
如今,基于物理机、Java 虚拟机或者非 Java 的其它高级语言虚拟机的语言,大多都会遵循这种基于现代编译原理的思路,在执行前先对程序源代码进行词法分析和语法分析处理,把源代码转化为抽象语法树。对于一门具体语言的实现来说,词法分析、语法分析以至后面的优化器和目标代码生成器都可以选择独立于执行引擎,形成一个完整意义的编译器去实现,这类代表是 C/C++。也可以为一个半独立的编译器,这类代表是 Java。又或者把这些步骤和执行全部封装在一个封闭的黑匣子中,如大多数的 JavaScript 执行器。
Java 语言中,Javac 编译器完成了程序代码经过词法分析、语法分析到抽象语法树、再遍历语法树生成字节码指令流的过程。因为这一部分动作是在 Java 虚拟机之外进行的,而解释器在虚拟机的内部,所以 Java 程序的编译就是半独立的实现。
许多 Java 虚拟机的执行引擎在执行 Java 代码的时候都有解释执行(通过解释器执行)和编译执行(通过即时编译器产生本地代码执行)两种选择。而对于最新的 Android 版本的执行模式则是 AOT + JIT + 解释执行,关于这方面我们后面有机会再聊。
基于栈的指令集与基于寄存器的指令集
Java 编译器输出的指令流,基本上是一种基于栈的指令集架构。基于栈的指令集主要的优点就是可移植,寄存器由硬件直接提供,程序直接依赖这些硬件寄存器则不可避免的要受到硬件约束。栈架构的指令集还有一些其他优点,比如相对更加紧凑(字节码中每个字节就对应一条指令,而多地址指令集中还需要存放参数)、编译实现更加简单(不需要考虑空间分配的问题,所有空间都是在栈上操作)等。
栈架构指令集的主要缺点是执行速度相对来说会稍慢一些。所有主流物理机的指令集都是寄存器架构也从侧面印证了这一点。
虽然栈架构指令集的代码非常紧凑,但是完成相同功能需要的指令集数量一般会比寄存器架构多,因为出栈、入栈操作本身就产生了相当多的指令数量。更重要的是,栈实现在内存中,频繁的栈访问也意味着频繁的内存访问,相对于处理器来说,内存始终是执行速度的瓶颈。由于指令数量和内存访问的原因,所以导致了栈架构指令集的执行速度会相对较慢。
正是基于上述原因,Android 虚拟机中采用了基于寄存器的指令集架构。不过有一点不同的是,前面说的是物理机上的寄存器,而 Android 上指的是虚拟机上的寄存器。
引用链接:https://juejin.cn/post/6844903871010045960
GitHub 上标星 10000+ 的开源知识库《二哥的 Java 进阶之路》第一版 PDF 终于来了!包括Java基础语法、数组&字符串、OOP、集合框架、Java IO、异常处理、Java 新特性、网络编程、NIO、并发编程、JVM等等,共计 32 万余字,500+张手绘图,可以说是通俗易懂、风趣幽默……详情戳:太赞了,GitHub 上标星 10000+ 的 Java 教程
微信搜 沉默王二 或扫描下方二维码关注二哥的原创公众号沉默王二,回复 222 即可免费领取。
