Java字节码指令详解,1 万字20 张图带你彻底掌握字节码指令
大家好,我是二哥呀。字节码指令是 JVM 体系中比较难啃的一块硬骨头,我估计有些球友会有这样的疑惑,“这么难啃,我还能学会啊?”
讲良心话,不是我谦虚,一开始学 Java 字节码和 Java 虚拟机方面的知识我也头大!但硬着头皮学了一阵子之后,突然就开窍了,觉得好有意思,尤其是明白了 Java 代码在底层竟然是这样执行的时候,感觉既膨胀又飘飘然,浑身上下散发着自信的光芒!
来吧,跟着二哥一起来学习吧,别畏难。前面我们已经讲过了,JVM 是基于栈结构的字节码指令集,那今天我们就来继续来学习,什么是字节码指令。
Java 的字节码指令由操作码和操作数组成:
- 操作码(Opcode):一个字节长度(0-255,意味着指令集的操作码总数不可能超过 256 条),代表着某种特定的操作含义。
- 操作数(Operands):零个或者多个,紧跟在操作码之后,代表此操作需要的参数。
由于 Java 虚拟机是基于栈而不是寄存器的结构,所以大多数字节码指令都只有一个操作码。比如 aload_0 就只有操作码没有操作数,而 invokespecial #1 则由操作码和操作数组成。
- aload_0:将局部变量表中下标为 0 的数据压入操作数栈中
- invokespecial #1:调用成员方法或者构造方法,并传递常量池中下标为 1 的常量
字节码指令主要有以下几种,分别是:
- 加载与存储指令
- 算术指令
- 类型转换指令
- 对象的创建与访问指令
- 方法调用和返回指令
- 操作数栈管理指令
- 控制转移指令
我们来一一说明下。
加载与存储指令
加载(load)和存储(store)指令是使用最频繁的指令,用于将数据从栈帧的局部变量表和操作数栈之间来回传递。
看下面这段代码。
public int add(int a, int b) {
int result = a + b;
return result;
}使用 javap 查看字节码指令(大致)如下:
public int add(int, int);
Code:
0: iload_1
1: iload_2
2: iadd
3: istore_3
4: ireturn我用下面一幅图来给大家说明白字节码指令的执行过程:
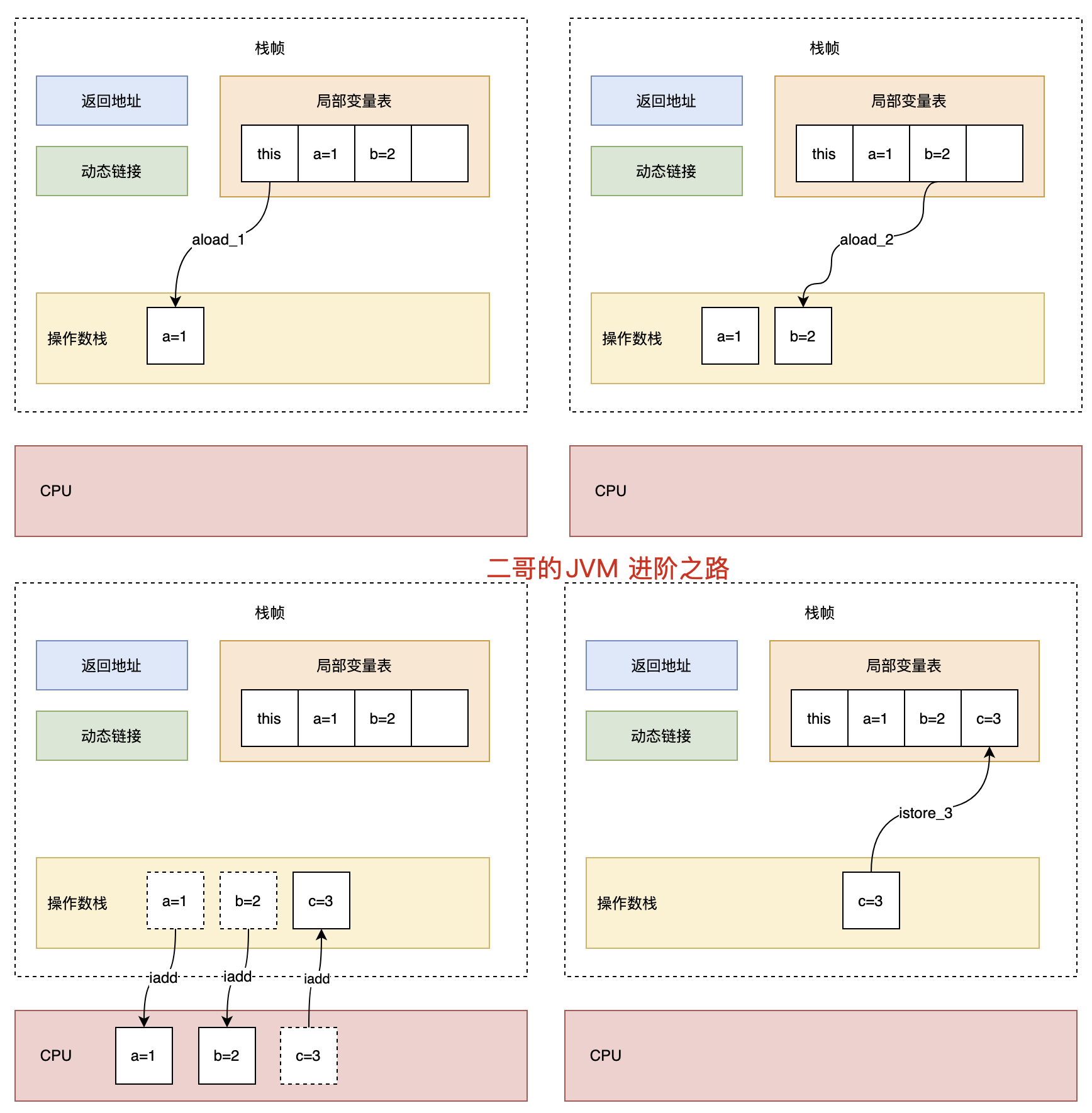
然后我们再来分析 load 和 store 指令的具体含义。
1)将局部变量表中的变量压入操作数栈中
xload_<n>(x 为 i、l、f、d、a,n 默认为 0 到 3),表示将第 n 个局部变量压入操作数栈中。- xload(x 为 i、l、f、d、a),通过指定参数的形式,将局部变量压入操作数栈中,当使用这个指令时,表示局部变量的数量可能超过了 4 个
解释一下。
x 为操作码助记符,表明是哪一种数据类型。见下表所示。
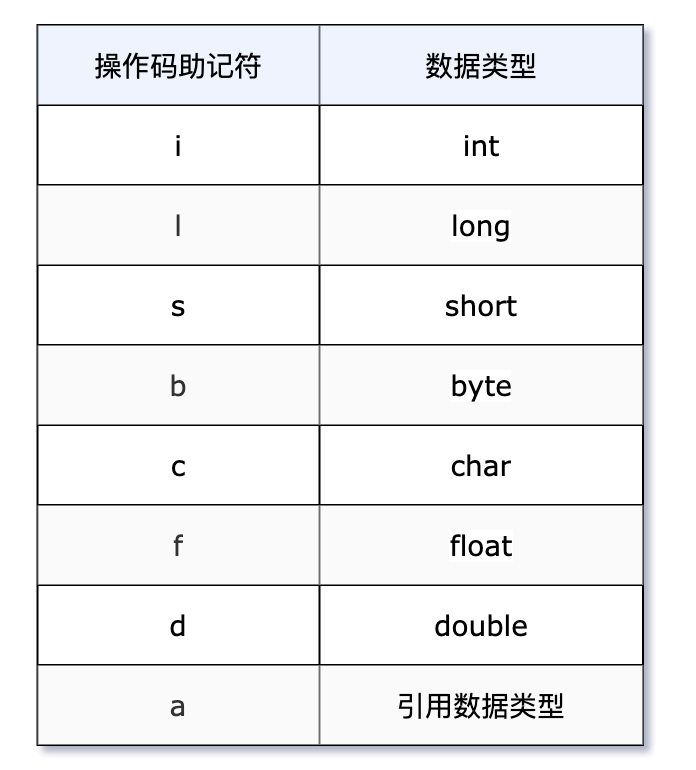
像 arraylength 指令,就没有操作码助记符,它没有代表数据类型的特殊字符,但操作数只能是一个数组类型的对象。
大部分的指令都不支持 byte、short 和 char,甚至没有任何指令支持 boolean 类型。编译器会将 byte 和 short 类型的数据带符号扩展(Sign-Extend)为 int 类型,将 boolean 和 char 零位扩展(Zero-Extend)为 int 类型。
举例来说。
private void load(int age, String name, long birthday, boolean sex) {
System.out.println(age + name + birthday + sex);
}通过 jclasslib 看一下 load() 方法(4 个参数)的字节码指令。
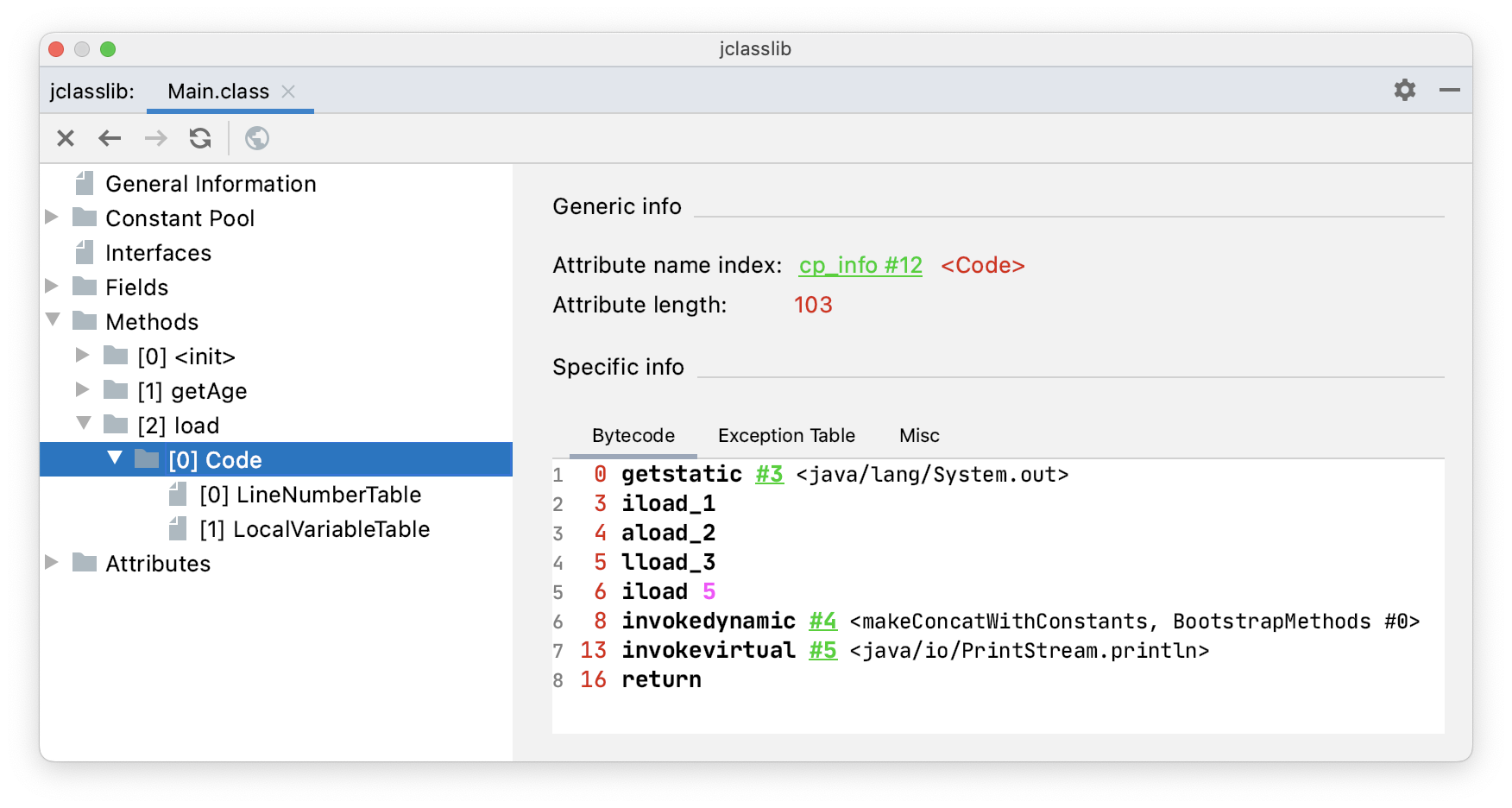
iload_1:将局部变量表中下标为 1 的 int 变量压入操作数栈中。aload_2:将局部变量表中下标为 2 的引用数据类型变量(此时为 String)压入操作数栈中。lload_3:将局部变量表中下标为 3 的 long 型变量压入操作数栈中。- iload 5:将局部变量表中下标为 5 的 int 变量(实际为 boolean)压入操作数栈中。
通过查看局部变量表就能关联上了。
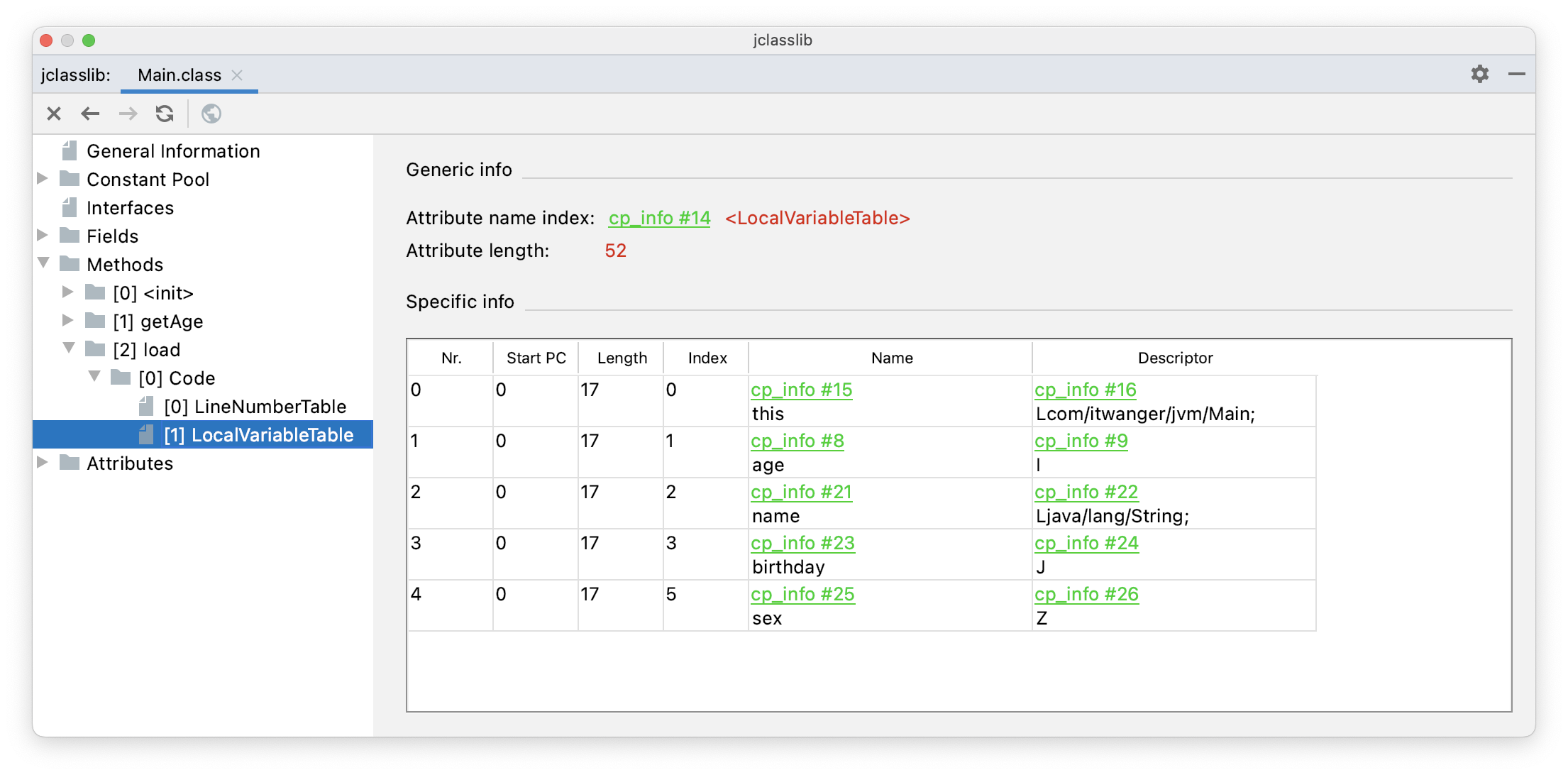
2)将常量池中的常量压入操作数栈中
根据数据类型和入栈内容的不同,又可以细分为 const 系列、push 系列和 Idc 指令。
const 系列,用于特殊的常量入栈,要入栈的常量隐含在指令本身。
push 系列,主要包括 bipush 和 sipush,前者接收 8 位整数作为参数,后者接收 16 位整数。
Idc 指令,当 const 和 push 不能满足的时候,万能的 Idc 指令就上场了,它接收一个 8 位的参数,指向常量池中的索引。
Idc_w:接收两个 8 位数,索引范围更大。- 如果参数是 long 或者 double,使用
Idc2_w指令。
举例来说。
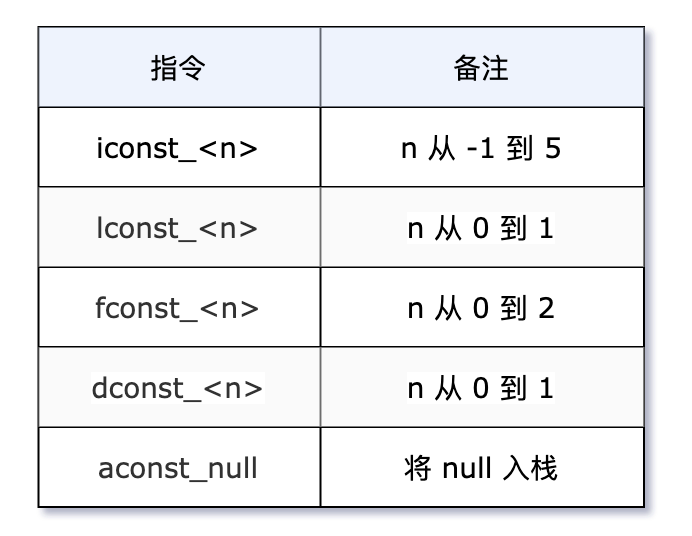
public void pushConstLdc() {
// 范围 [-1,5]
int iconst = -1;
// 范围 [-128,127]
int bipush = 127;
// 范围 [-32768,32767]
int sipush= 32767;
// 其他 int
int ldc = 32768;
String aconst = null;
String IdcString = "沉默王二";
}通过 jclasslib 看一下 pushConstLdc() 方法的字节码指令。
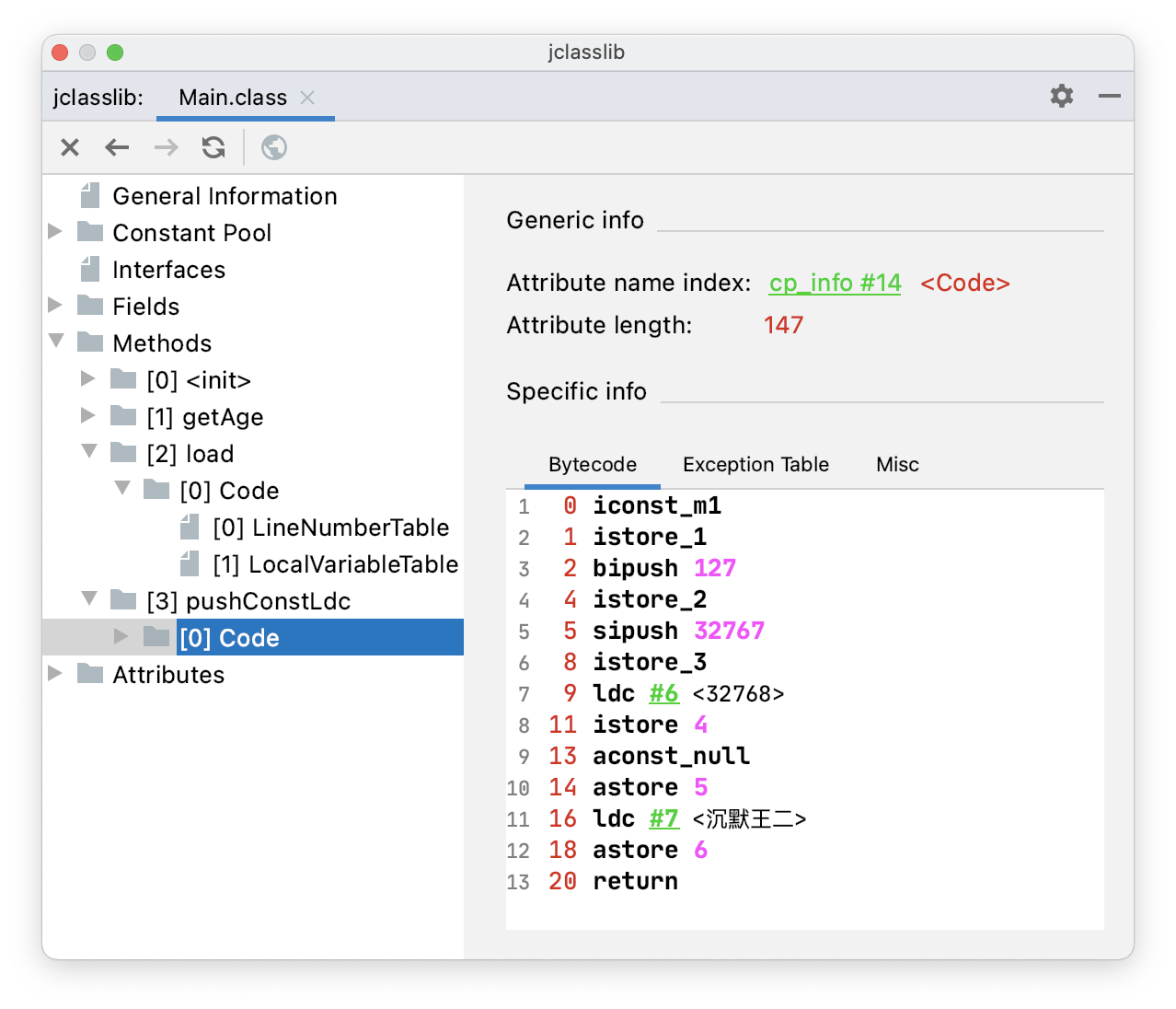
iconst_m1:将 -1 入栈。范围 [-1,5]。- bipush 127:将 127 入栈。范围 [-128,127]。
- sipush 32767:将 32767 入栈。范围 [-32768,32767]。
ldc #6 <32768>:将常量池中下标为 6 的常量 32768 入栈。- aconst_null:将 null 入栈。
ldc #7 <沉默王二>:将常量池中下标为 7 的常量“沉默王二”入栈。
3)将栈顶的数据出栈并装入局部变量表中
主要是用来给局部变量赋值,这类指令主要以 store 的形式存在。
xstore_<n>(x 为 i、l、f、d、a,n 默认为 0 到 3)- xstore(x 为 i、l、f、d、a)
明白了 xload_<n> 和 xload,再看 xstore_<n> 和 xstore 就会轻松得多,作用反了一下而已。
大家来想一个问题,为什么要有 xstore_<n> 和 xload_<n> 呢?它们的作用和 xstore n、xload n 不是一样的吗?
xstore_<n> 和 xstore n 的区别在于,前者相当于只有操作码,占用 1 个字节;后者相当于由操作码和操作数组成,操作码占 1 个字节,操作数占 2 个字节,一共占 3 个字节。
由于局部变量表中前几个位置总是非常常用,虽然 xstore_<n> 和 xload_<n> 增加了指令数量,但字节码的体积变小了!
举例来说。
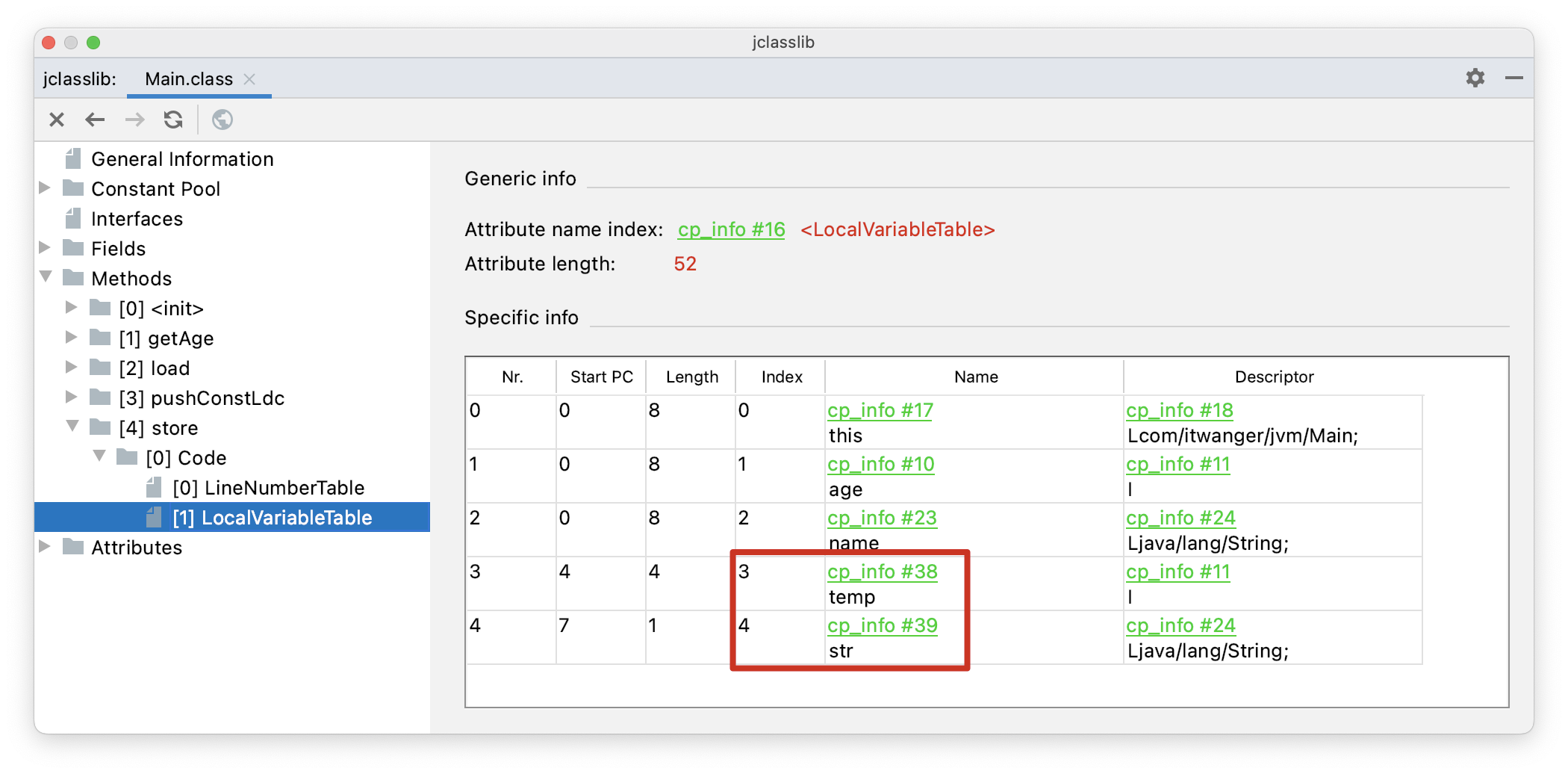
public void store(int age, String name) {
int temp = age + 2;
String str = name;
}通过 jclasslib 看一下 store() 方法的字节码指令。
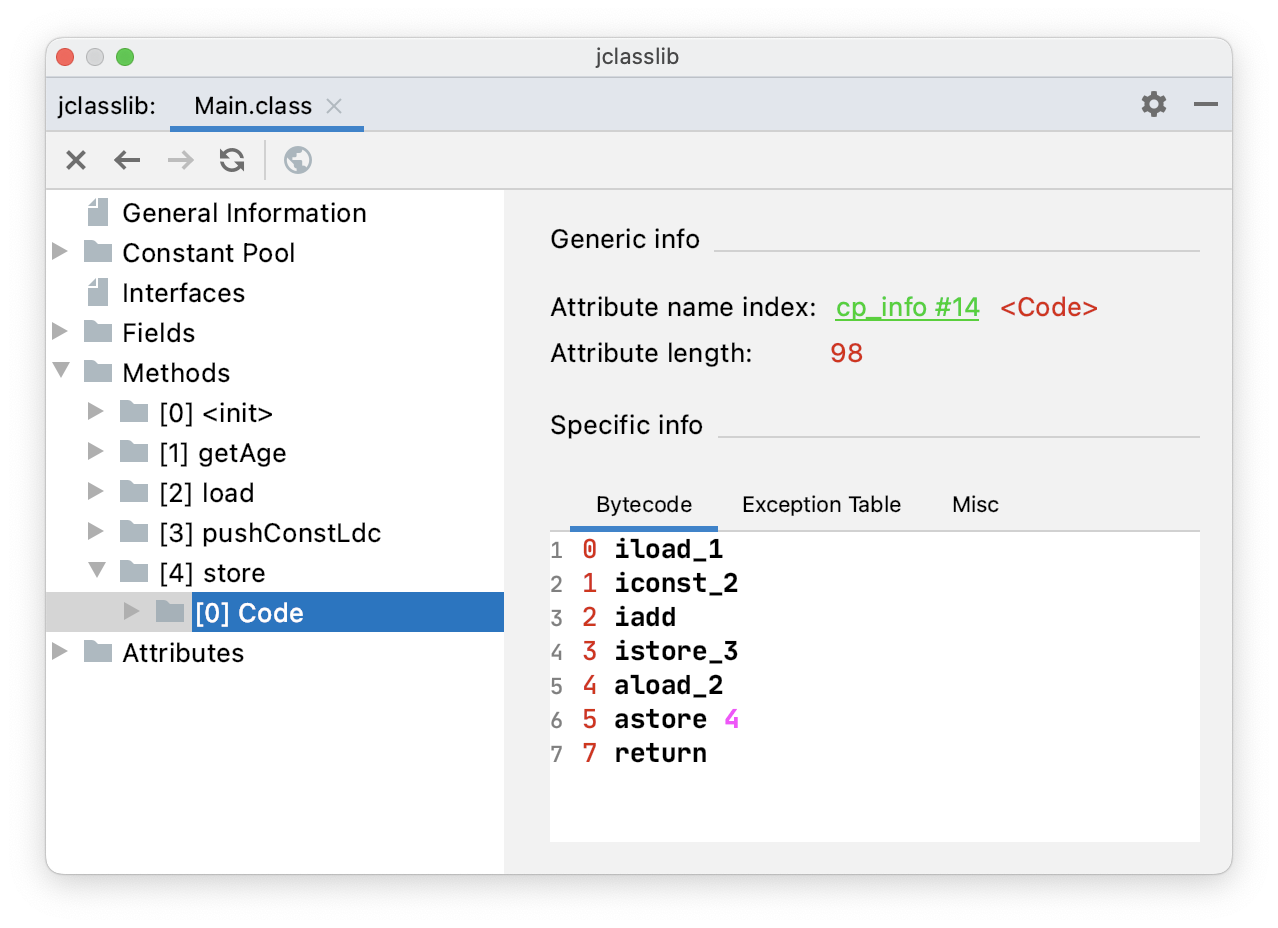
istore_3:从操作数中弹出一个整数,并把它赋值给局部变量表中索引为 3 的变量。- astore 4:从操作数中弹出一个引用数据类型,并把它赋值给局部变量表中索引为 4 的变量。
通过查看局部变量表就能关联上了。
算术指令
算术指令用于对两个操作数栈上的值进行某种特定运算,并把结果重新压入操作数栈。可以分为两类:整型数据的运算指令和浮点数据的运算指令。
这一节可以回顾一下 Java 运算符 ,就可以把一些非常简单的算术运算和 JVM 关联起来了。
需要注意的是,数据运算可能会导致溢出,比如两个很大的正整数相加,很可能会得到一个负数。但 Java 虚拟机规范中并没有对这种情况给出具体结果,因此程序是不会显式报错的。所以,大家在开发过程中,如果涉及到较大的数据进行加法、乘法运算的时候,一定要注意!
当发生溢出时,将会使用有符号的无穷大 Infinity 来表示;如果某个操作结果没有明确的数学定义的话,将会使用 NaN 值来表示。而且所有使用 NaN 作为操作数的算术操作,结果都会返回 NaN。
举例来说。
public void infinityNaN() {
int i = 10;
double j = i / 0.0;
System.out.println(j); // Infinity
double d1 = 0.0;
double d2 = d1 / 0.0;
System.out.println(d2); // NaN
}- 任何一个非零的数除以浮点数 0(注意不是 int 类型),可以想象结果是无穷大 Infinity 的。
- 把这个非零的数换成 0 的时候,结果又不太好定义,就用 NaN 值来表示。
Java 虚拟机提供了两种运算模式:
- 向最接近数舍入:在进行浮点数运算时,所有的结果都必须舍入到一个适当的精度,不是特别精确的结果必须舍入为可被表示的最接近的精确值,如果有两种可表示的形式与该值接近,将优先选择最低有效位为零的(类似四舍五入)。
- 向零舍入:将浮点数转换为整数时,采用该模式,该模式将在目标数值类型中选择一个最接近但是不大于原值的数字作为最精确的舍入结果(类似取整)。
我把所有的算术指令列一下:
- 加法指令:iadd、ladd、fadd、dadd
- 减法指令:isub、lsub、fsub、dsub
- 乘法指令:imul、lmul、fmul、dmul
- 除法指令:idiv、ldiv、fdiv、ddiv
- 求余指令:irem、lrem、frem、drem
- 自增指令:iinc
举例来说。
public void calculate(int age) {
int add = age + 1;
int sub = age - 1;
int mul = age * 2;
int div = age / 3;
int rem = age % 4;
age++;
age--;
}通过 jclasslib 看一下 calculate() 方法的字节码指令。
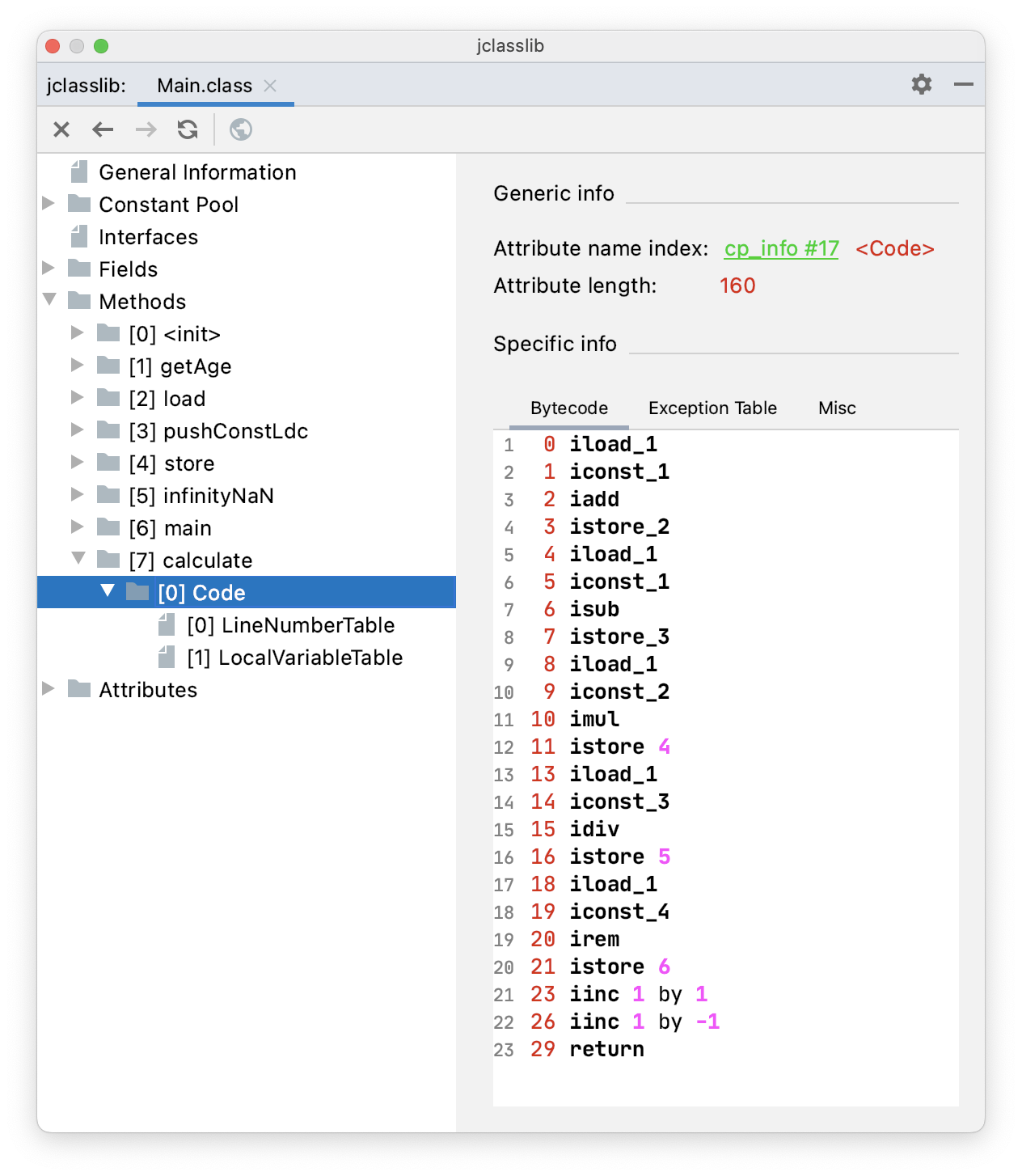
- iadd,加法
- isub,减法
- imul,乘法
- idiv,除法
- irem,取余
- iinc,自增的时候 +1,自减的时候 -1
类型转换指令
类型转换指令可以分为两种:
1)宽化,小类型向大类型转换,比如 int–>long–>float–>double,对应的指令有:i2l、i2f、i2d、l2f、l2d、f2d。
- 从 int 到 long,或者从 int 到 double,是不会有精度丢失的;
- 从 int、long 到 float,或者 long 到 double 时,可能会发生精度丢失;
- 从 byte、char 和 short 到 int 的宽化类型转换实际上是隐式发生的,这样可以减少字节码指令,毕竟字节码指令只有 256 个,占一个字节。
2)窄化,大类型向小类型转换,比如从 int 类型到 byte、short 或者 char,对应的指令有:i2b、i2s、i2c;从 long 到 int,对应的指令有:l2i;从 float 到 int 或者 long,对应的指令有:f2i、f2l;从 double 到 int、long 或者 float,对应的指令有:d2i、d2l、d2f。
- 窄化很可能会发生精度丢失,毕竟是不同的数量级;
- 但 Java 虚拟机并不会因此抛出运行时异常。
可以回想一下前面讲过的:自动类型转换与强制类型转换
举例来说。
public void updown() {
int i = 10;
double d = i;
float f = 10f;
long ong = (long)f;
}通过 jclasslib 看一下 updown() 方法的字节码指令。
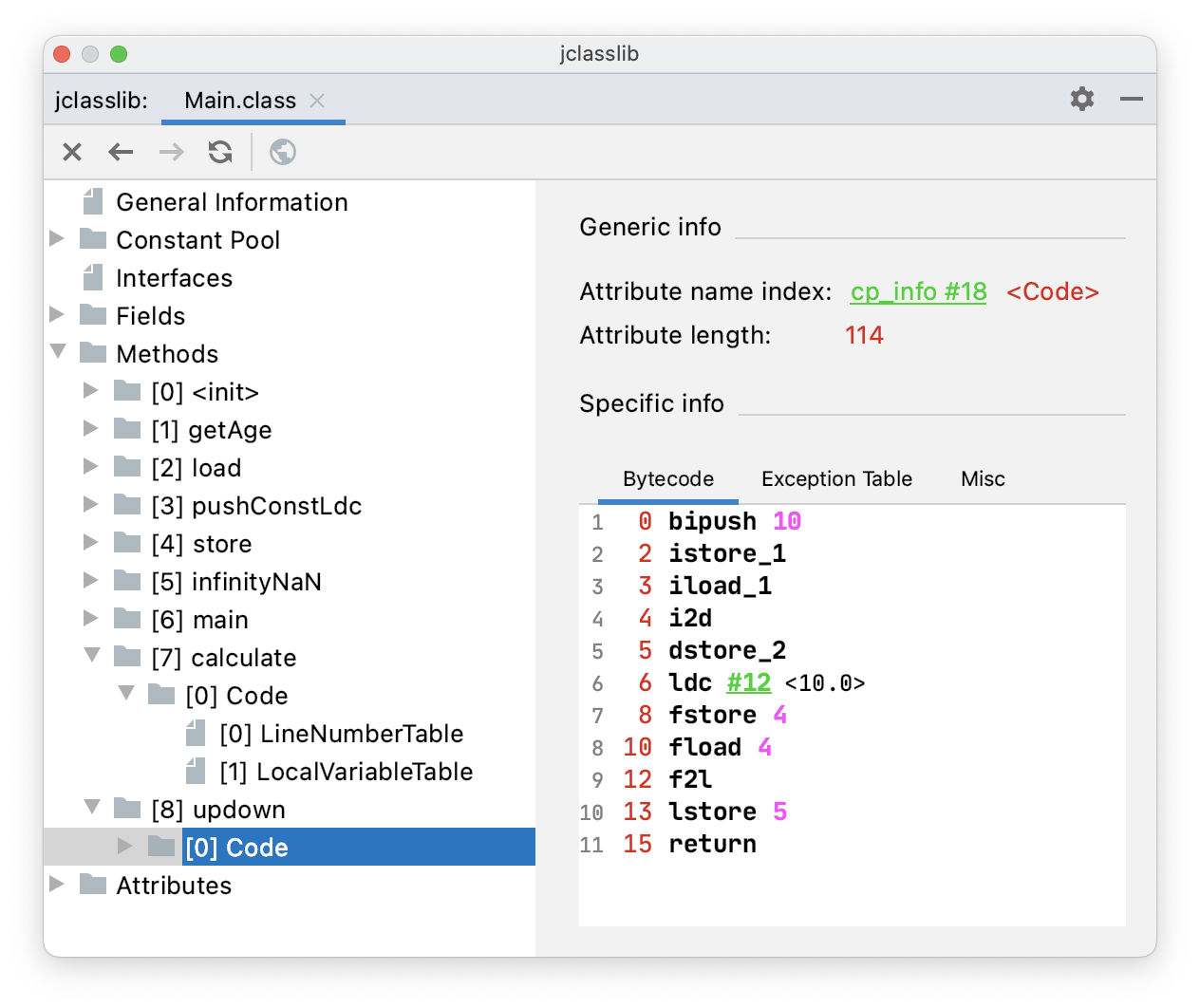
- i2d,int 宽化为 double
- f2l, float 窄化为 long
对象的创建和访问指令
Java 是一门面向对象的编程语言,那么 Java 虚拟机是如何从字节码层面进行支持的呢?
1)创建指令
数组是一种特殊的对象,它创建的字节码指令和普通对象的创建指令不同。创建数组的指令有三种:
- newarray:创建基本数据类型的数组
- anewarray:创建引用类型的数组
- multianewarray:创建多维数组
而对象的创建指令只有一个,就是 new,它会接收一个操作数,指向常量池中的一个索引,表示要创建的类型。
举例来说。
public void newObject() {
String name = new String("沉默王二");
File file = new File("无愁河的浪荡汉子.book");
int [] ages = {};
}通过 jclasslib 看一下 newObject() 方法的字节码指令。
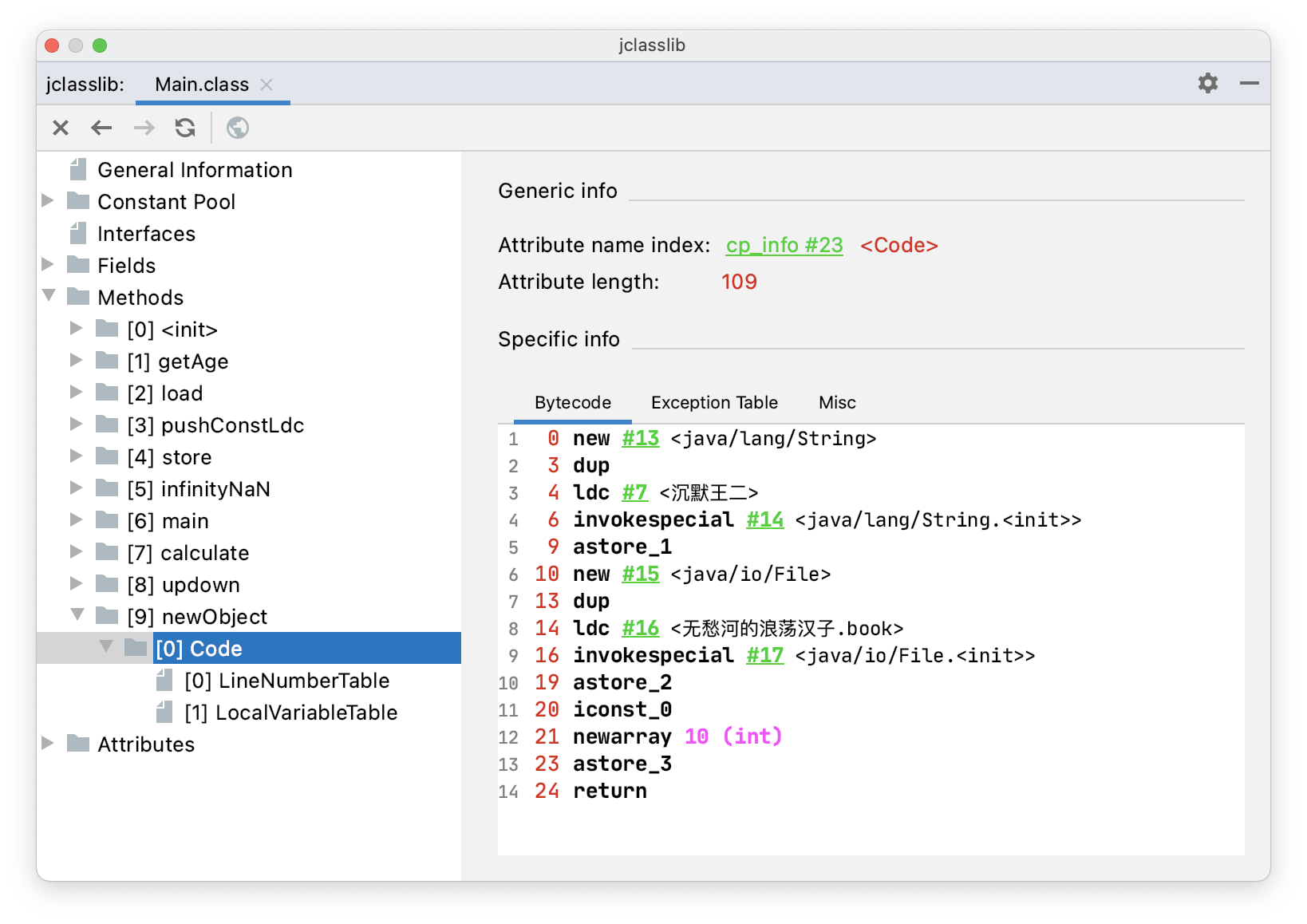
new #13 <java/lang/String>,创建一个 String 对象。new #15 <java/io/File>,创建一个 File 对象。newarray 10 (int),创建一个 int 类型的数组。
2)字段访问指令
字段可以分为两类,一类是成员变量,一类是静态变量(也就是类变量),所以字段访问指令可以分为两类:
- 访问静态变量:getstatic、putstatic。
- 访问成员变量:getfield、putfield,需要创建对象后才能访问。
举例来说。
public class Writer {
private String name;
static String mark = "作者";
public static void main(String[] args) {
print(mark);
Writer w = new Writer();
print(w.name);
}
public static void print(String arg) {
System.out.println(arg);
}
}通过 jclasslib 看一下 main() 方法的字节码指令。
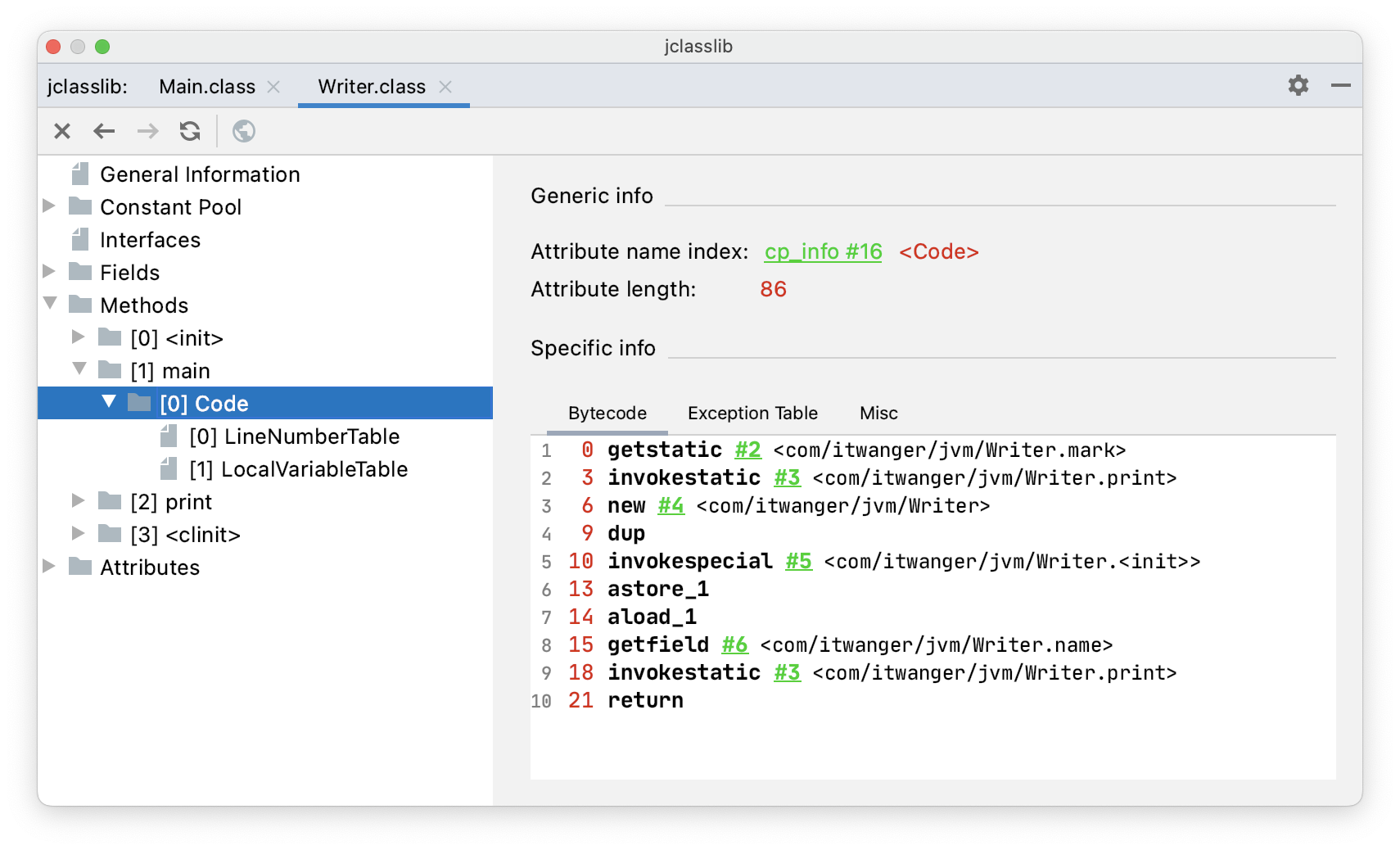
getstatic #2 <com/itwanger/jvm/Writer.mark>,访问静态变量 markgetfield #6 <com/itwanger/jvm/Writer.name>,访问成员变量 name
方法调用和返回指令
方法调用指令有 5 个,分别用于不同的场景:
- invokevirtual:用于调用对象的成员方法,根据对象的实际类型进行分派,支持多态。
- invokeinterface:用于调用接口方法,会在运行时搜索由特定对象实现的接口方法进行调用。
- invokespecial:用于调用一些需要特殊处理的方法,包括构造方法、私有方法和父类方法。
- invokestatic:用于调用静态方法。
- invokedynamic:用于在运行时动态解析出调用点限定符所引用的方法,并执行。
举例来说。
public class InvokeExamples {
private void run() {
List ls = new ArrayList();
ls.add("难顶");
ArrayList als = new ArrayList();
als.add("学不动了");
}
public static void print() {
System.out.println("invokestatic");
}
public static void main(String[] args) {
print();
InvokeExamples invoke = new InvokeExamples();
invoke.run();
}
}我们用 javap -c InvokeExamples.class 来反编译一下。
Compiled from "InvokeExamples.java"
public class com.itwanger.jvm.InvokeExamples {
public com.itwanger.jvm.InvokeExamples();
Code:
0: aload_0
1: invokespecial #1 // Method java/lang/Object."<init>":()V
4: return
private void run();
Code:
0: new #2 // class java/util/ArrayList
3: dup
4: invokespecial #3 // Method java/util/ArrayList."<init>":()V
7: astore_1
8: aload_1
9: ldc #4 // String 难顶
11: invokeinterface #5, 2 // InterfaceMethod java/util/List.add:(Ljava/lang/Object;)Z
16: pop
17: new #2 // class java/util/ArrayList
20: dup
21: invokespecial #3 // Method java/util/ArrayList."<init>":()V
24: astore_2
25: aload_2
26: ldc #6 // String 学不动了
28: invokevirtual #7 // Method java/util/ArrayList.add:(Ljava/lang/Object;)Z
31: pop
32: return
public static void print();
Code:
0: getstatic #8 // Field java/lang/System.out:Ljava/io/PrintStream;
3: ldc #9 // String invokestatic
5: invokevirtual #10 // Method java/io/PrintStream.println:(Ljava/lang/String;)V
8: return
public static void main(java.lang.String[]);
Code:
0: invokestatic #11 // Method print:()V
3: new #12 // class com/itwanger/jvm/InvokeExamples
6: dup
7: invokespecial #13 // Method "<init>":()V
10: astore_1
11: aload_1
12: invokevirtual #14 // Method run:()V
15: return
}InvokeExamples 类有 4 个方法,包括缺省的构造方法在内。
1)invokespecial
缺省的构造方法内部会调用超类 Object 的初始化构造方法:
`invokespecial #1 // Method java/lang/Object."<init>":()V`2)invokeinterface和invokevirtual
invokeinterface #5, 2 // InterfaceMethod java/util/List.add:(Ljava/lang/Object;)Z由于 ls 变量的引用类型为接口 List,所以 ls.add() 调用的是 invokeinterface 指令,等运行时再确定是不是接口 List 的实现对象 ArrayList 的 add() 方法。
invokevirtual #7 // Method java/util/ArrayList.add:(Ljava/lang/Object;)Z由于 als 变量的引用类型已经确定为 ArrayList,所以 als.add() 方法调用的是 invokevirtual 指令。
3)invokestatic
invokestatic #11 // Method print:()Vprint() 方法是静态的,所以调用的是 invokestatic 指令。
invokedynamic
invokedynamic 指令是 Java 7 引入的,主要是为了支持动态语言,比如 Groovy、Scala、JRuby 等。这些语言都是在运行时动态解析出调用点限定符所引用的方法,并执行。
看下面这段代码,用到了 Lambda 表达式,Lambda 表达式的实现就依赖于 invokedynamic 指令:
import java.util.function.Function;
public class LambdaExample {
public static void main(String[] args) {
// 使用 Lambda 表达式定义一个函数
Function<Integer, Integer> square = x -> x * x;
// 调用这个函数
int result = square.apply(5);
System.out.println(result); // 输出 25
}
}在这个例子中,Lambda 表达式 x -> x * x 定义了一个接受一个整数并返回其平方的函数。在编译这段代码时,编译器会使用 invokedynamic 指令来动态地绑定这个 Lambda 表达式。
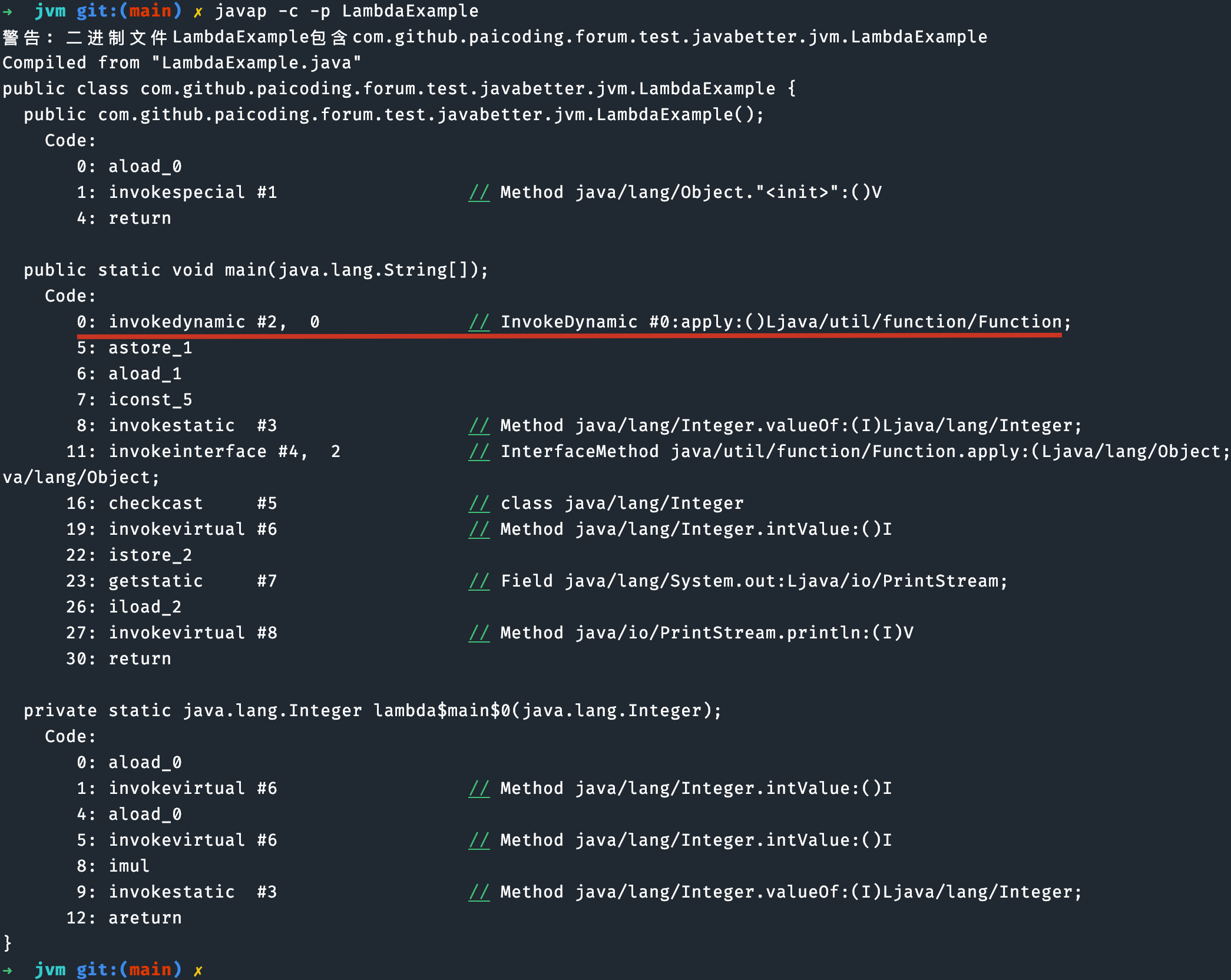
①、invokedynamic #2, 0:使用 invokedynamic 调用一个引导方法(Bootstrap Method),这个方法负责实现并返回一个 Function 接口的实例。这里的 Lambda 表达式 x -> x * x 被转换成了一个 Function 对象。引导方法在首次执行时会被调用,它负责生成一个 CallSite,该 CallSite 包含了指向具体实现 Lambda 表达式的方法句柄(Method Handle)。在这个例子中,这个方法句柄指向了 lambda$main$0 方法。
②、astore_1:将 invokedynamic 指令的结果(Lambda 表达式的 Function 对象)存储到局部变量表的位置 1。
③、Lambda 表达式的实现是:lambda$main$0,这是 Lambda 表达式 x -> x * x 的实际实现。它接收一个 Integer 对象作为参数,计算其平方,然后返回结果。
public class LambdaExample {
public LambdaExample() {
}
public static void main(String[] args) {
Function<Integer, Integer> square = (x) -> {
return x * x;
};
int result = (Integer)square.apply(5);
System.out.println(result);
}
}其他指令这里就不再分析下去了,大家可以尝试一下,检验自己的学习成果。
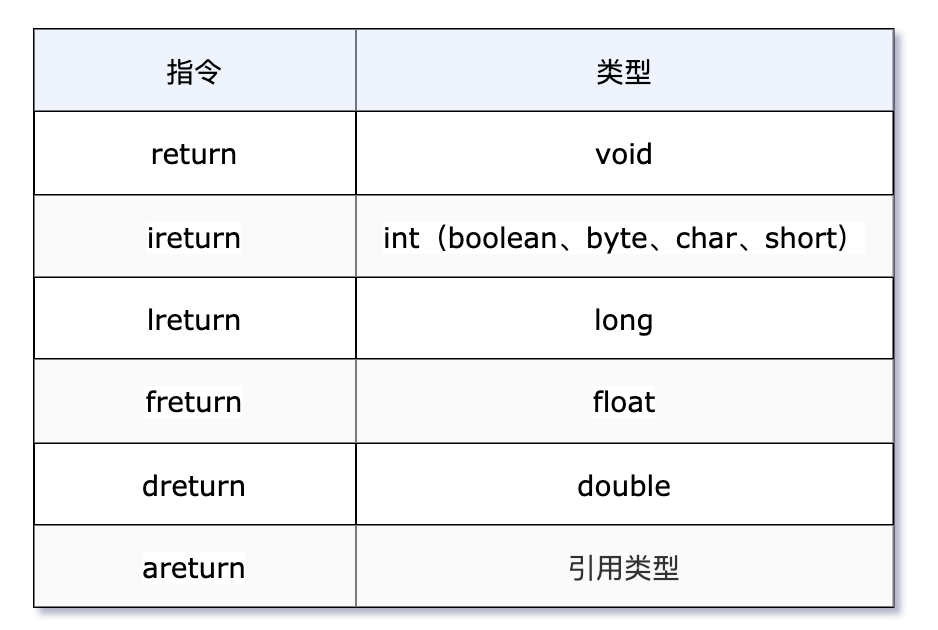
方法返回指令
方法返回指令根据方法的返回值类型进行区分,常见的返回指令见下图,就是各种 return。
操作数栈管理指令
常见的操作数栈管理指令有 pop、dup 和 swap。
- 将一个或两个元素从栈顶弹出,并且直接废弃,比如 pop,pop2;
- 复制栈顶的一个或两个数值并将其重新压入栈顶,比如 dup,dup2,
dup*×1,dup2*×1,dup*×2,dup2*×2; - 将栈最顶端的两个槽中的数值交换位置,比如 swap。
这些指令不需要指明数据类型,因为是按照位置压入和弹出的。
举例来说。
public class Dup {
int age;
public int incAndGet() {
return ++age;
}
}通过 jclasslib 看一下 incAndGet() 方法的字节码指令。
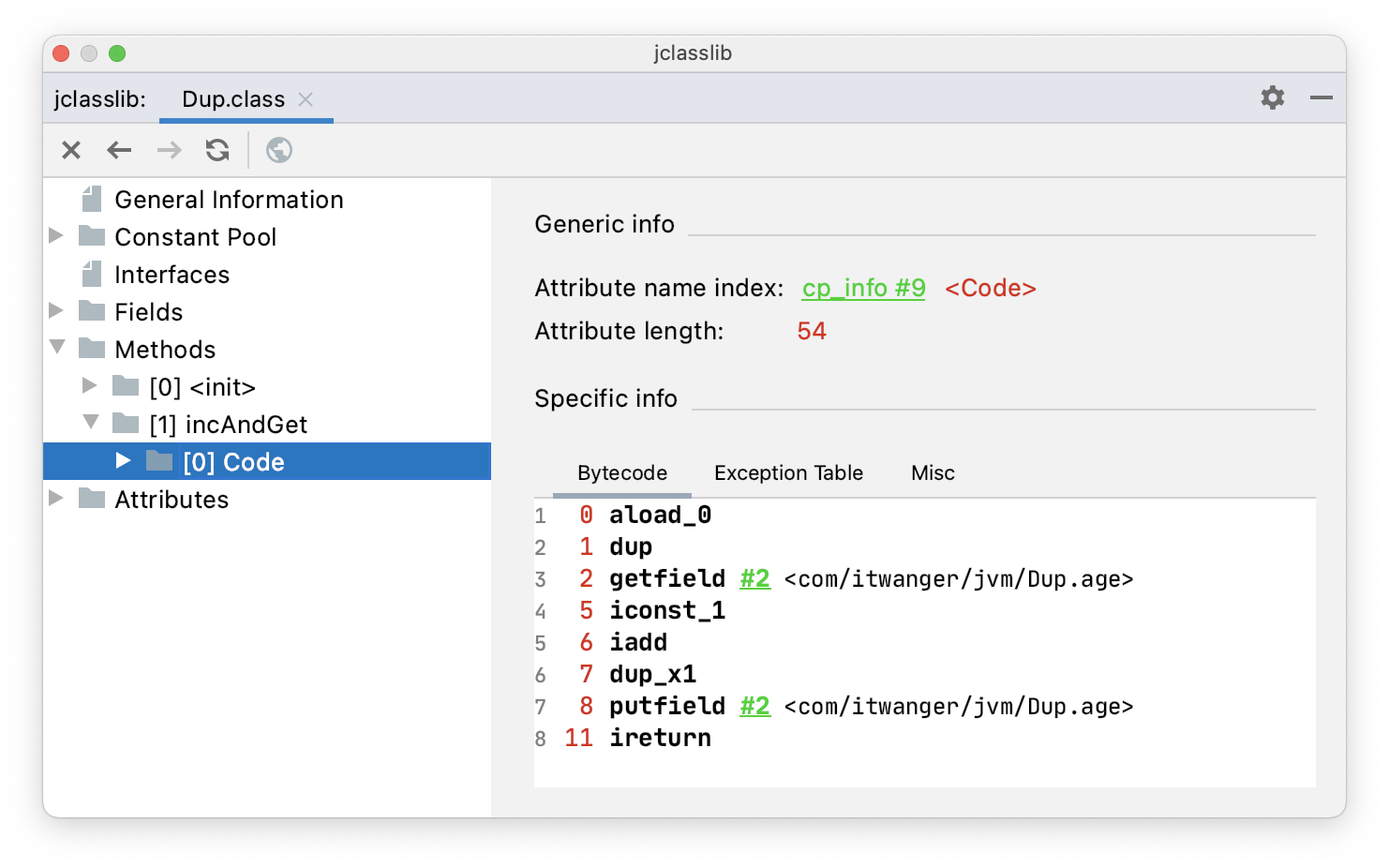
aload_0:将 this 入栈。- dup:复制栈顶的 this。
getfield #2:将常量池中下标为 2 的常量加载到栈上,同时将一个 this 出栈。iconst_1:将常量 1 入栈。- iadd:将栈顶的两个值相加后出栈,并将结果放回栈上。
dup_x1:复制栈顶的元素,并将其插入 this 下面。putfield #2: 将栈顶的两个元素出栈,并将其赋值给字段 age。- ireturn:将栈顶的元素出栈返回。
控制转移指令
控制转移指令包括:
- 比较指令,比较栈顶的两个元素的大小,并将比较结果入栈。
- 条件跳转指令,通常和比较指令一块使用,在条件跳转指令执行前,一般先用比较指令进行栈顶元素的比较,然后进行条件跳转。
- 比较条件转指令,类似于比较指令和条件跳转指令的结合体,它将比较和跳转两个步骤合二为一。
- 多条件分支跳转指令,专为 switch-case 语句设计的。
- 无条件跳转指令,目前主要是 goto 指令。
和之前学过《流程控制语句》就关联了起来。
1)比较指令
比较指令有:dcmpg,dcmpl、fcmpg、fcmpl、lcmp,指令的第一个字母代表的含义分别是 double、float、long。注意,没有 int 类型。
对于 double 和 float 来说,由于 NaN 的存在,有两个版本的比较指令。拿 float 来说,有 fcmpg 和 fcmpl,区别在于,如果遇到 NaN,fcmpg 会将 1 压入栈,fcmpl 会将 -1 压入栈。
举例来说。
public void lcmp(long a, long b) {
if(a > b){}
}通过 jclasslib 看一下 lcmp() 方法的字节码指令。
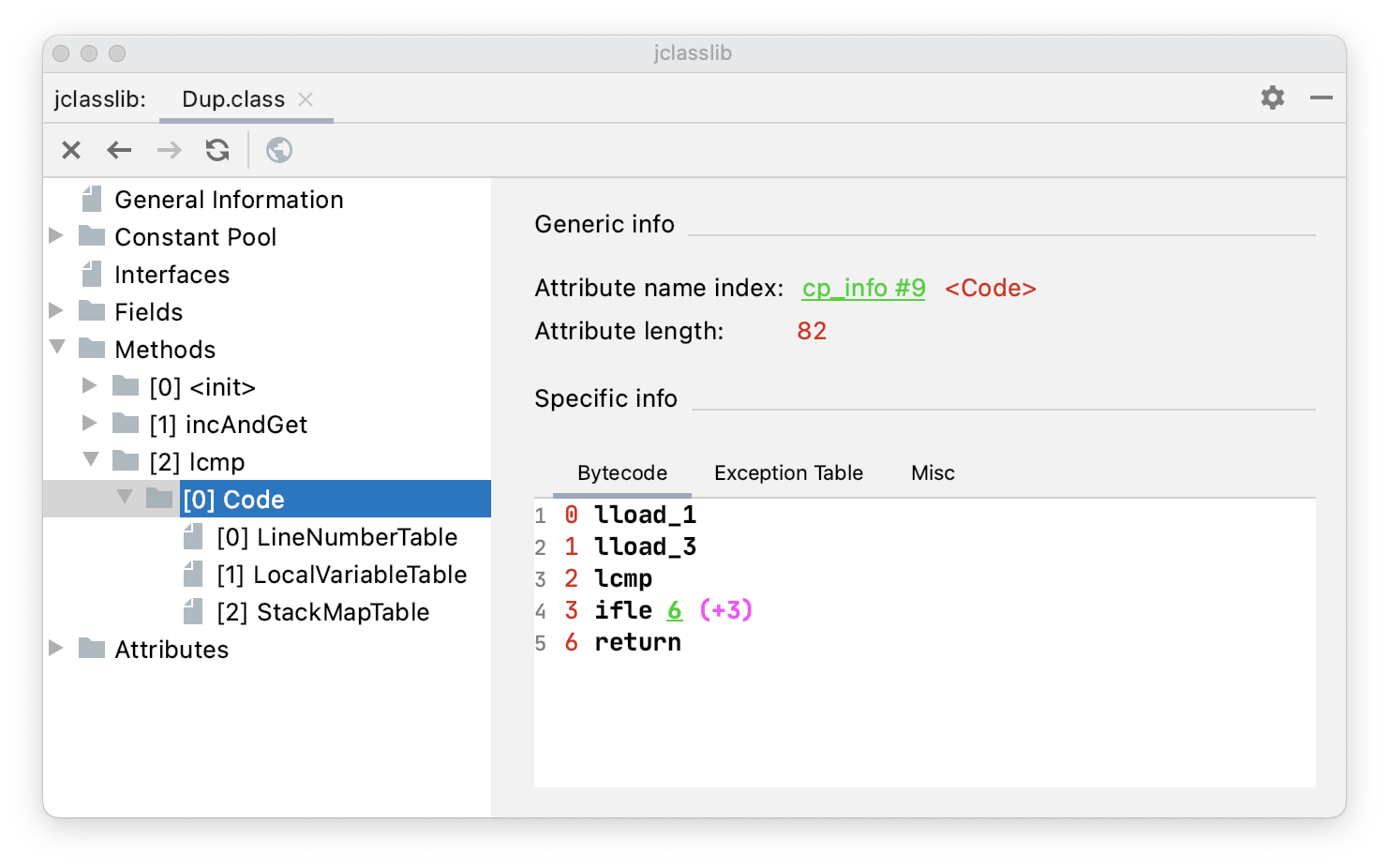
lcmp 用于两个 long 型的数据进行比较。
2)条件跳转指令
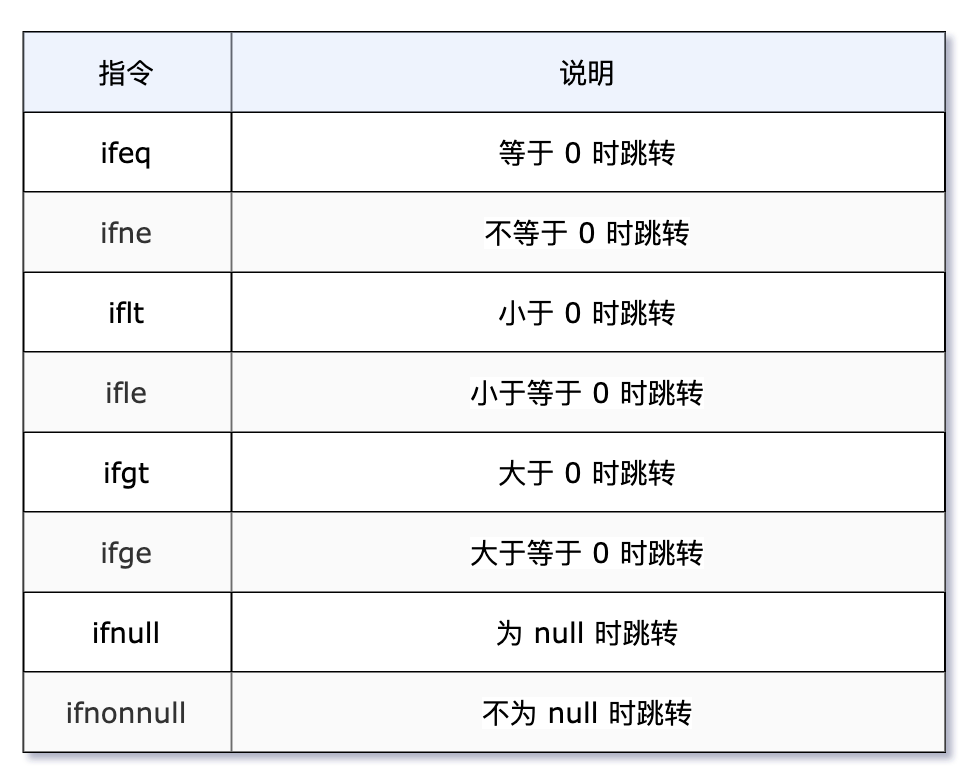
这些指令都会接收两个字节的操作数,它们的统一含义是,弹出栈顶元素,测试它是否满足某一条件,满足的话,跳转到对应位置。
对于 long、float 和 double 类型的条件分支比较,会先执行比较指令返回一个整型值到操作数栈中后再执行 int 类型的条件跳转指令。
对于 boolean、byte、char、short,以及 int,则直接使用条件跳转指令来完成。
举例来说。
public void fi() {
int a = 0;
if (a == 0) {
a = 10;
} else {
a = 20;
}
}通过 jclasslib 看一下 fi() 方法的字节码指令。
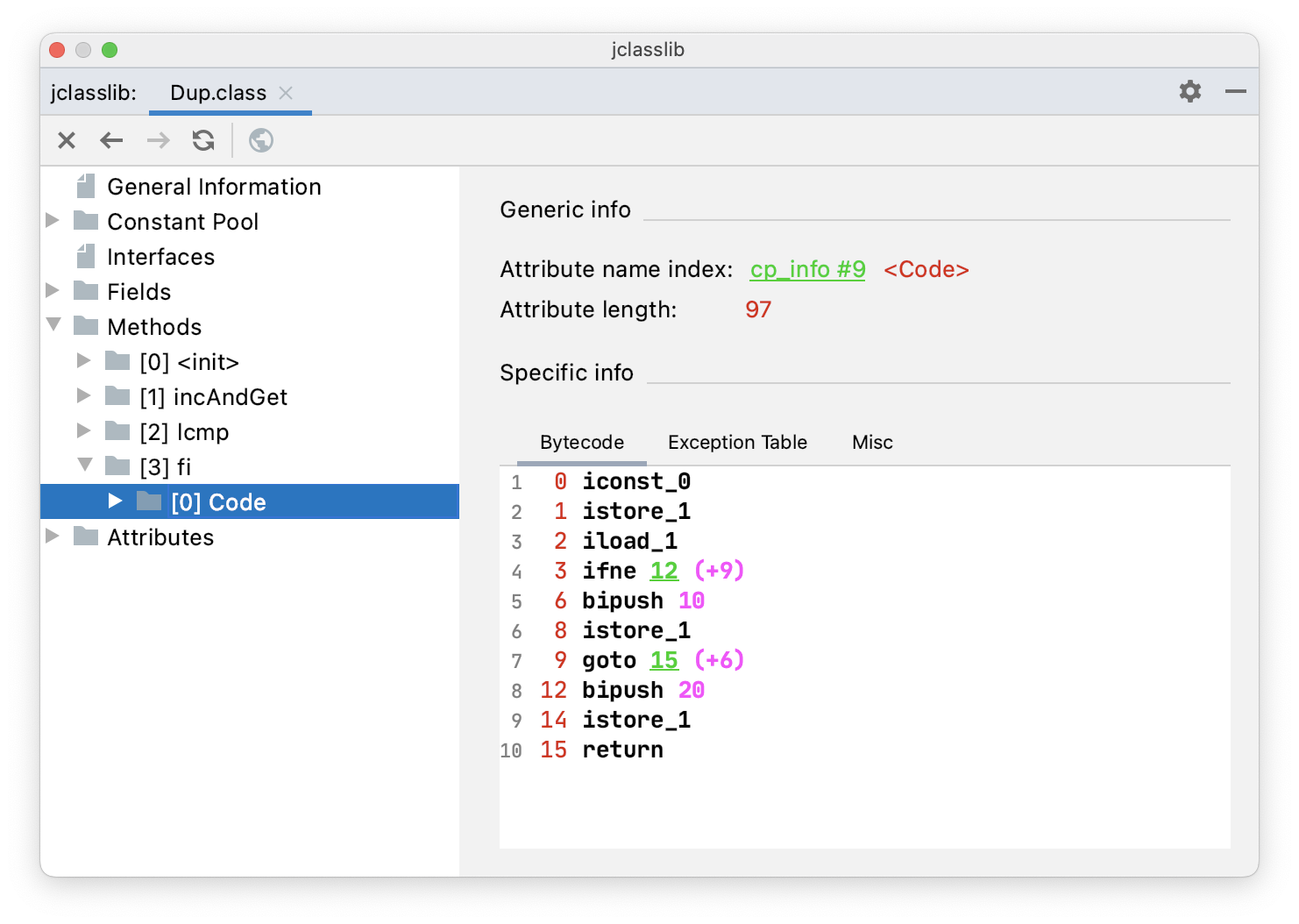
3 ifne 12 (+9) 的意思是,如果栈顶的元素不等于 0,跳转到第 12(3+9)行 12 bipush 20。
3)比较条件转指令
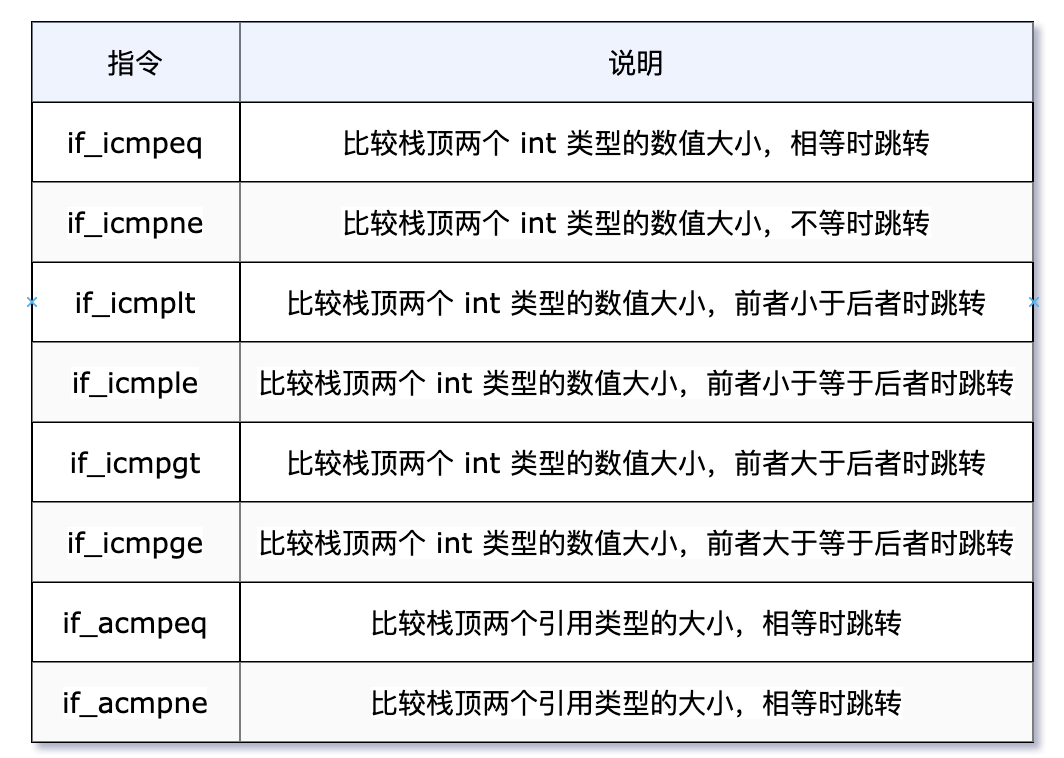
前缀“if_”后,以字符“i”开头的指令针对 int 型整数进行操作,以字符“a”开头的指令表示对象的比较。
举例来说。
public void compare() {
int i = 10;
int j = 20;
System.out.println(i > j);
}通过 jclasslib 看一下 compare() 方法的字节码指令。
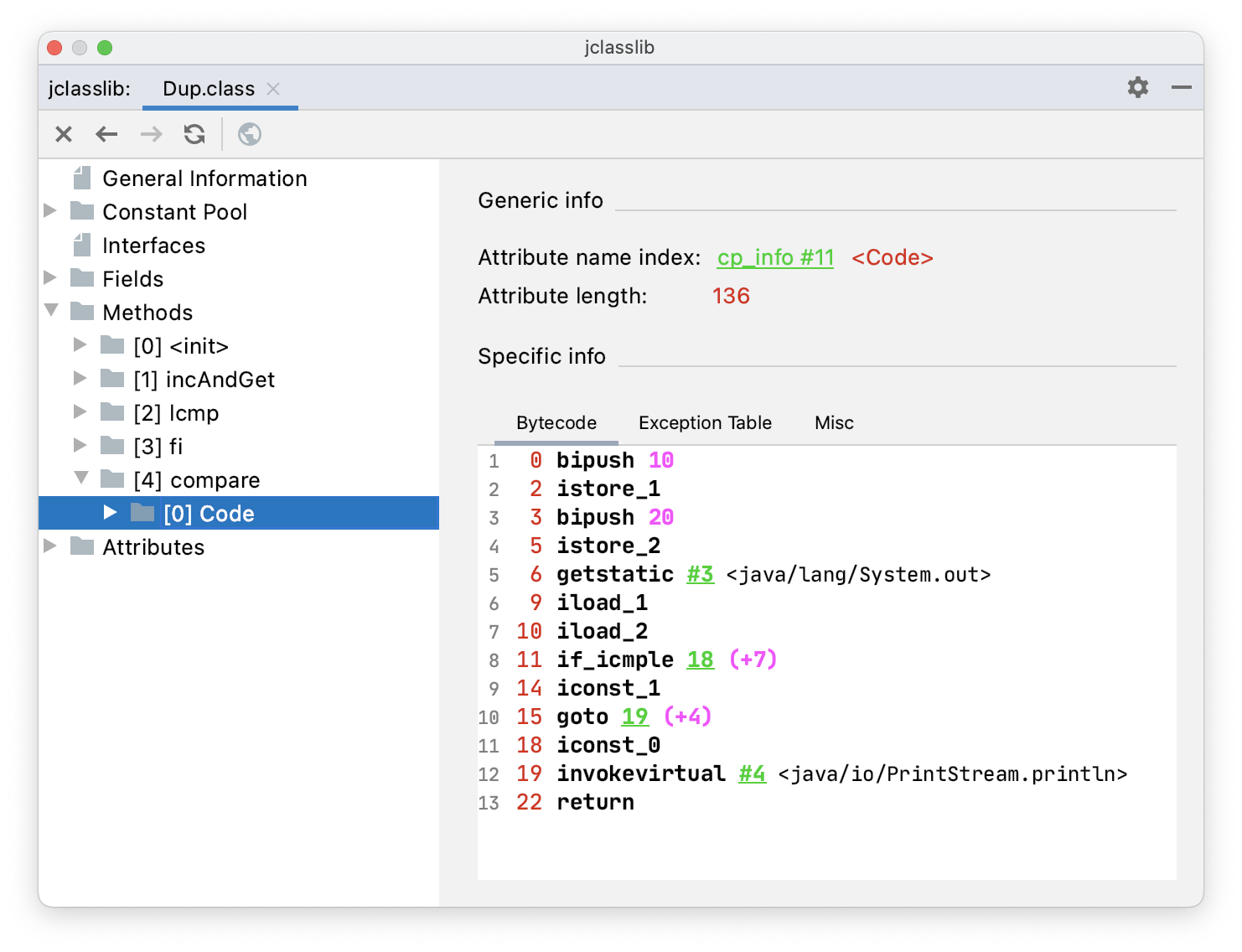
11 if_icmple 18 (+7) 的意思是,如果栈顶的两个 int 类型的数值比较的话,如果前者小于后者时跳转到第 18 行(11+7)。
4)多条件分支跳转指令
主要有 tableswitch 和 lookupswitch,前者要求多个条件分支值是连续的,它内部只存放起始值和终止值,以及若干个跳转偏移量,通过给定的操作数 index,可以立即定位到跳转偏移量位置,因此效率比较高;后者内部存放着各个离散的 case-offset 对,每次执行都要搜索全部的 case-offset 对,找到匹配的 case 值,并根据对应的 offset 计算跳转地址,因此效率较低。
举例来说。
public void switchTest(int select) {
int num;
switch (select) {
case 1:
num = 10;
break;
case 2:
case 3:
num = 30;
break;
default:
num = 40;
}
}通过 jclasslib 看一下 switchTest() 方法的字节码指令。
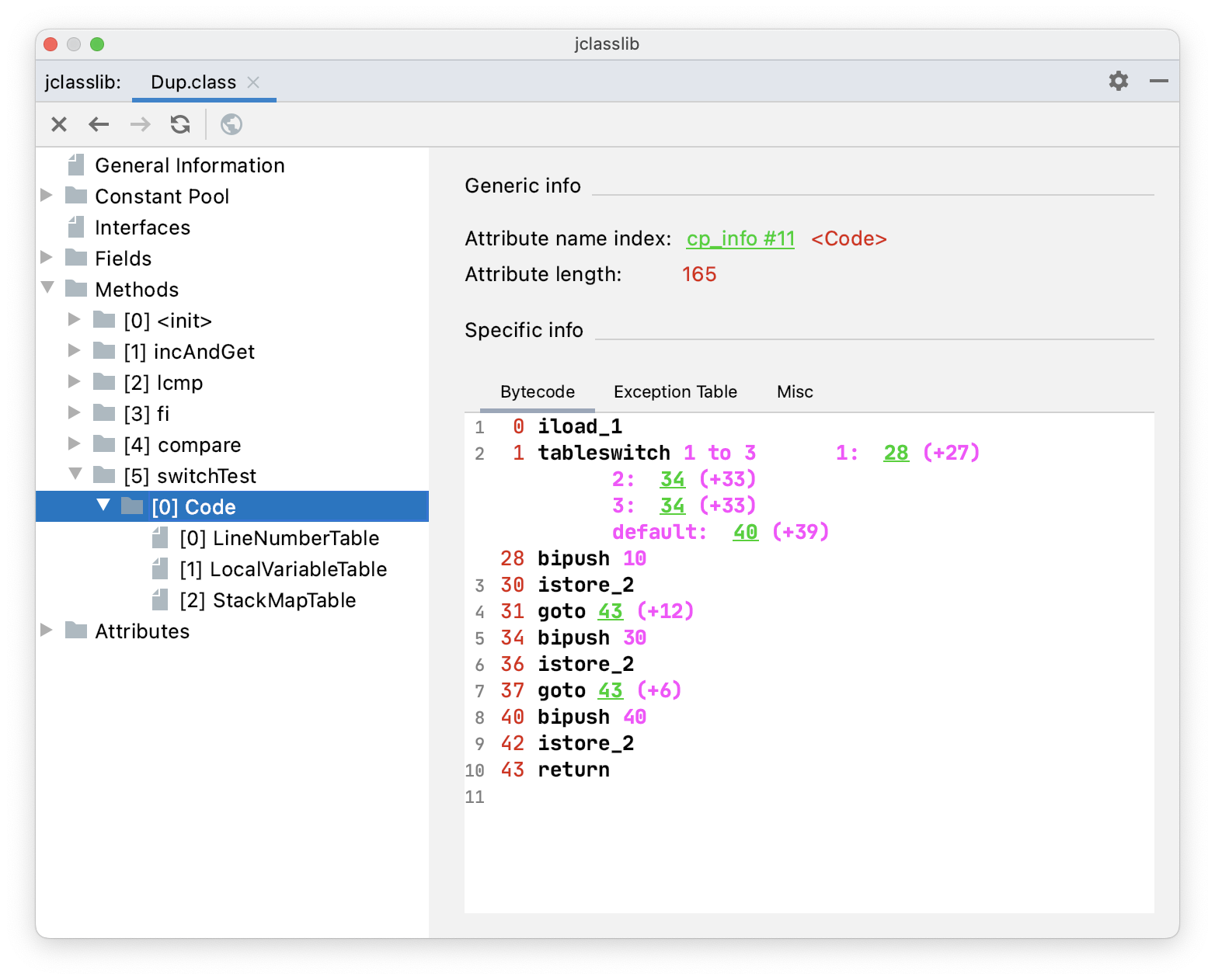
case 2 的时候没有 break,所以 case 2 和 case 3 是连续的,用的是 tableswitch。如果等于 1,跳转到 28 行;如果等于 2 和 3,跳转到 34 行,如果是 default,跳转到 40 行。
5)无条件跳转指令
goto 指令接收两个字节的操作数,共同组成一个带符号的整数,用于指定指令的偏移量,指令执行的目的就是跳转到偏移量给定的位置处。
前面的例子里都出现了 goto 的身影,也很好理解。如果指令的偏移量特别大,超出了两个字节的范围,可以使用指令 goto_w,接收 4 个字节的操作数。
异常处理时的字节码指令
让我们通过一个简单的 Java 代码示例来说明异常处理时的字节码指令。
public class ExceptionExample {
public void testException() {
try {
int a = 1 / 0; // 这将导致除以零的异常
} catch (ArithmeticException e) {
System.out.println("发生算术异常");
}
}
}编译上述代码后,使用 javap -c ExceptionExample 可以查看其字节码,大致如下:
public void testException();
Code:
0: iconst_1
1: iconst_0
2: idiv
3: istore_1
4: goto 12
7: astore_1
8: getstatic #2 // Field java/lang/System.out:Ljava/io/PrintStream;
11: ldc #3 // String 发生算术异常
13: invokevirtual #4 // Method java/io/PrintStream.println:(Ljava/lang/String;)V
16: return
Exception table:
from to target type
0 4 7 Class java/lang/ArithmeticException①、除法
0: iconst_1、1: iconst_0、2: idiv 这三个指令是执行除法运算 1 / 0。前两个指令将常数 1 和 0 分别推送到操作数栈,然后 idiv 指令执行除法操作。
3: istore_1 将除法的结果存储到局部变量表中(这里会发生异常,指令实际上不会执行)。
②、异常处理
4: goto 12:在 try 块的末尾,有一个 goto 指令跳过 catch 块的代码。
7: astore_1 这是 catch 块的开始。如果捕获到异常,将异常对象存储到局部变量表。
8 - 13: getstatic, ldc, invokevirtual 这些指令执行 System.out.println("发生算术异常")。
16: return 方法返回。
Exception table 这部分定义了异常处理器。在这个例子中,当在字节码偏移量 0 到 4 之间发生 ArithmeticException 时,控制跳转到偏移量 7,即 catch 块的开始。
详细大家经过这里例子可以和前面学过的《异常处理》关联起来。
synchronized 的字节码指令
好,我们再来看一个关于 synchronized 关键字的示例,就一个简单的同步代码块:
public class SynchronizedExample {
public void syncBlockMethod() {
synchronized(this) {
// 同步块体
}
}
}对应的字节码大致如下:
public void syncBlockMethod();
Code:
0: aload_0
1: dup
2: astore_1
3: monitorenter
4: aload_1
5: monitorexit
6: goto 14
9: astore 2
11: aload_1
12: monitorexit
13: aload 2
15: athrow
16: return
Exception table:
from to target type
4 6 9 any
9 13 9 anymonitorenter / monitorexit 这两个指令用于同步块的开始和结束。monitorenter 指令用于获取对象的监视器锁,monitorexit 指令用于释放锁。
希望大家通过这个简单的示例,把前面学过的《synchronized》关键字关联起来。
小结
路漫漫其修远兮,吾将上下而求索。
这节我们详细地介绍了 Java 字节码指令,包括算术指令、类型转换指令、对象的创建和访问指令、方法调用和返回指令、操作数栈管理指令、控制转移指令、异常处理时的字节码指令、synchronized 的字节码指令等。
想要走得更远,Java 字节码指令这块就必须得硬碰硬地吃透,希望二哥的这些分享可以帮助到大家~
GitHub 上标星 10000+ 的开源知识库《二哥的 Java 进阶之路》第一版 PDF 终于来了!包括 Java 基础语法、数组&字符串、OOP、集合框架、Java IO、异常处理、Java 新特性、网络编程、NIO、并发编程、JVM 等等,共计 32 万余字,500+张手绘图,可以说是通俗易懂、风趣幽默……详情戳:太赞了,GitHub 上标星 10000+ 的 Java 教程
微信搜 沉默王二 或扫描下方二维码关注二哥的原创公众号沉默王二,回复 222 即可免费领取。
