Spring Boot 整合 JPA
Spring Data JPA 简介
Spring Data 是 Spring 提供的一个操作数据的框架,Spring Data JPA是 Spring Data 下的一个基于 JPA 标准的操作数据的模块。
JPA(Java Persistence API)是 Java 亲妈 Sun 公司提出的一套 Java 持久化规范。所谓规范,就是只定义标准,不提供实现。
JPA 的提出主要是为了整合市面上已有的 ORM 框架,比如说 Hibernate、EclipseLink 等。官方觉得你们搞框架可以,但不要乱搞,得按照我的标准来。
Spring Data JPA 只是一个抽象层,它上接 JPA 下接 ORM 框架,通过基于 JPA 的 Respository 接口极大地减少了 JPA 作为数据访问方案的代码量,简化了持久层开发并且屏蔽了各大 ORM 框架的差异。
总结一下就是:
- JPA 是规范,统一了规范才便于使用。
- Hibernate 是 JPA 的实现,是一套成熟的 ORM 框架。
- Spring Data JPA 是 Spring 提出的,它增加了一个抽象层,用来屏蔽不同 ORM 框架的差异。
Spring Boot 整合 Spring Data JPA
第一步,在 pom.xml 文件中添加 JPA 的 starter 依赖。
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>第二步,在 application.yml 文件中添加数据库连接信息。
spring:
datasource:
username: codingmore-mysql
password: dddd
url: jdbc:mysql://xxxx:3306/codingmore-mysql?useUnicode=true&characterEncoding=utf-8&serverTimezone=Asia/Shanghai&useSSL=false第三步,新建实体类 User.java。
@Data
@Entity
@Table(name = "user")
public class User {
@Id
private Integer id;
private Integer age;
private String name;
private String password;
}@Data注解为 lombok 注解,会自动为该类添加 getter/setter 方法。@Entity和@Table注解都是 JDK 1.5 以后引入的元数据注解,遵循 JPA 规范中定义的查询语言 JPQL,类似 SQL 语法,适用于 Java 类。@Entity表明该类是一个实体类,默认使用 ORM 规则,即类名为数据库表名,类中的字段名为数据库表中的字段名。@Table注解是非必选项,它的优先级高于@Entity注解,比如说@Entity(name="user")和@Table(name="users")同时存在的话,对应的表名为 users。@Id表名该字段为主键字段,当声明了 @Entity 注解,@Id就必须也得声明。
这里推荐大家在 Intellij IDEA 中安装 JPA Buddy 插件,该插件提供了可视化的代码生成器,可以帮我们简化 JPA 的开发工作。
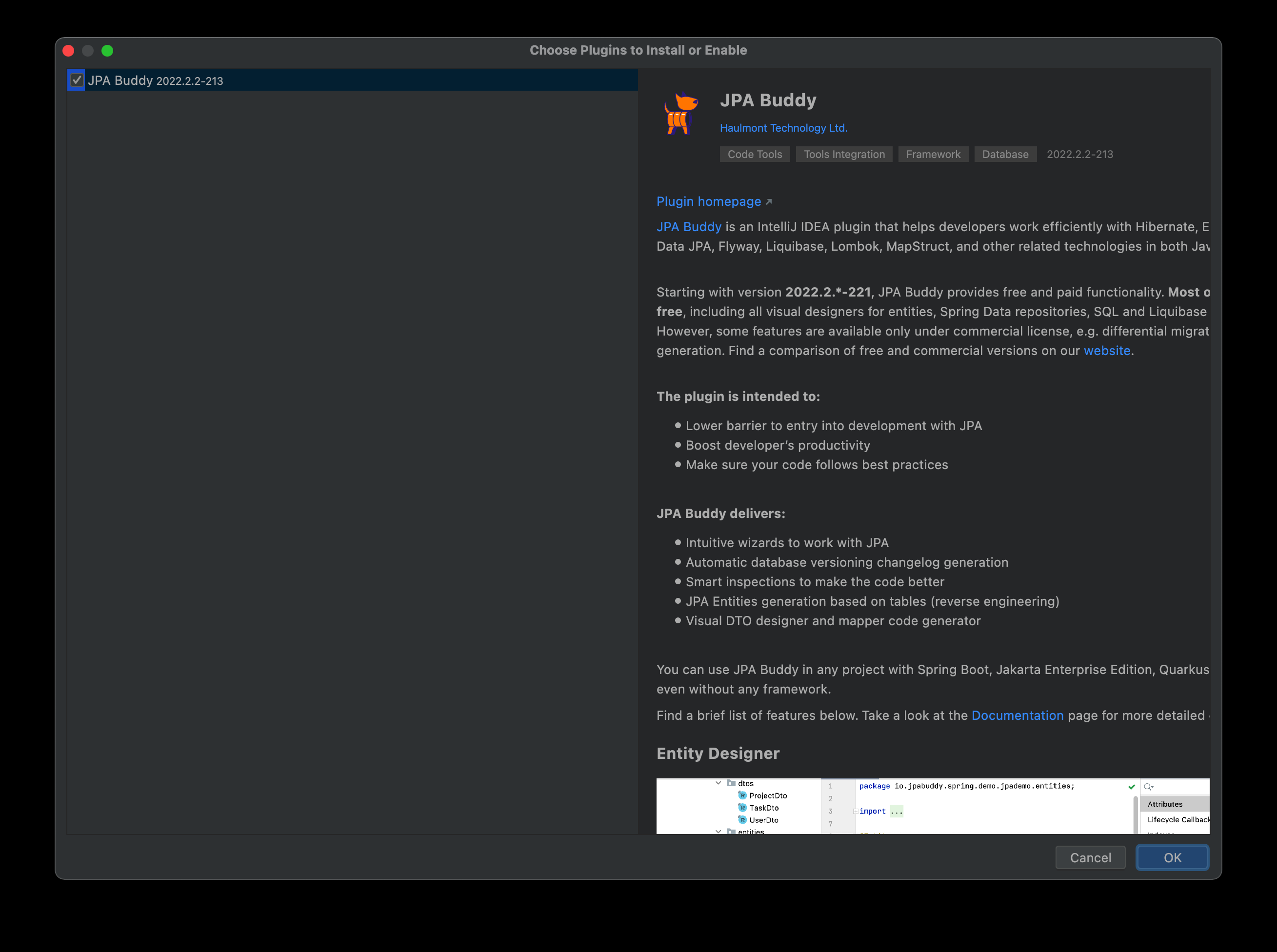
安装完 JPA Buddy 插件后,当我们创建好实体类后,会自动打开三个面板:JPA Structure,JPA Palette和JPA Inspector。
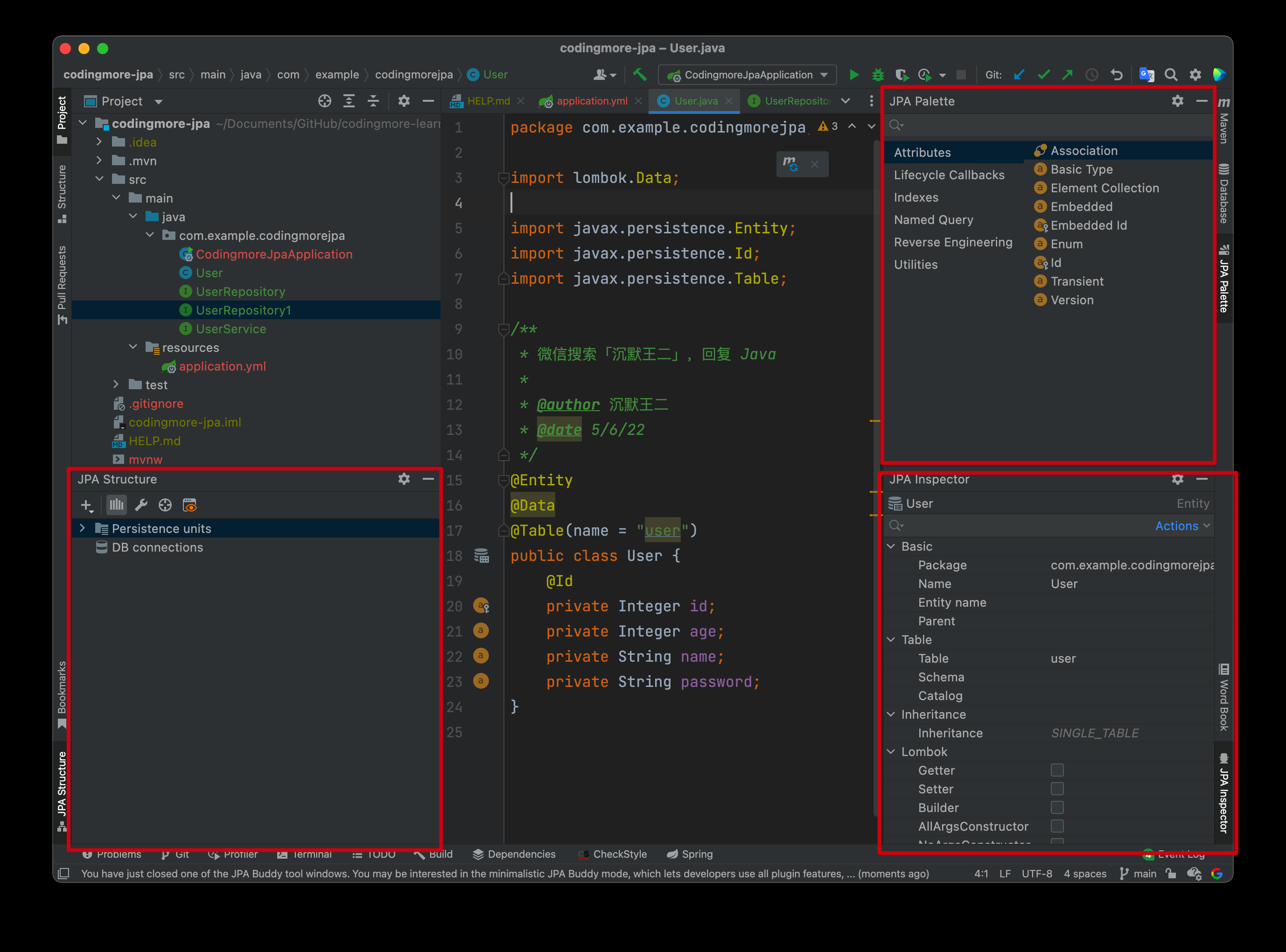
在JPA Buddy 插件的帮助下,我们其实可以直接在项目的目录上右键选择通过 JPA 的方式创建实体类。
选择数据表。
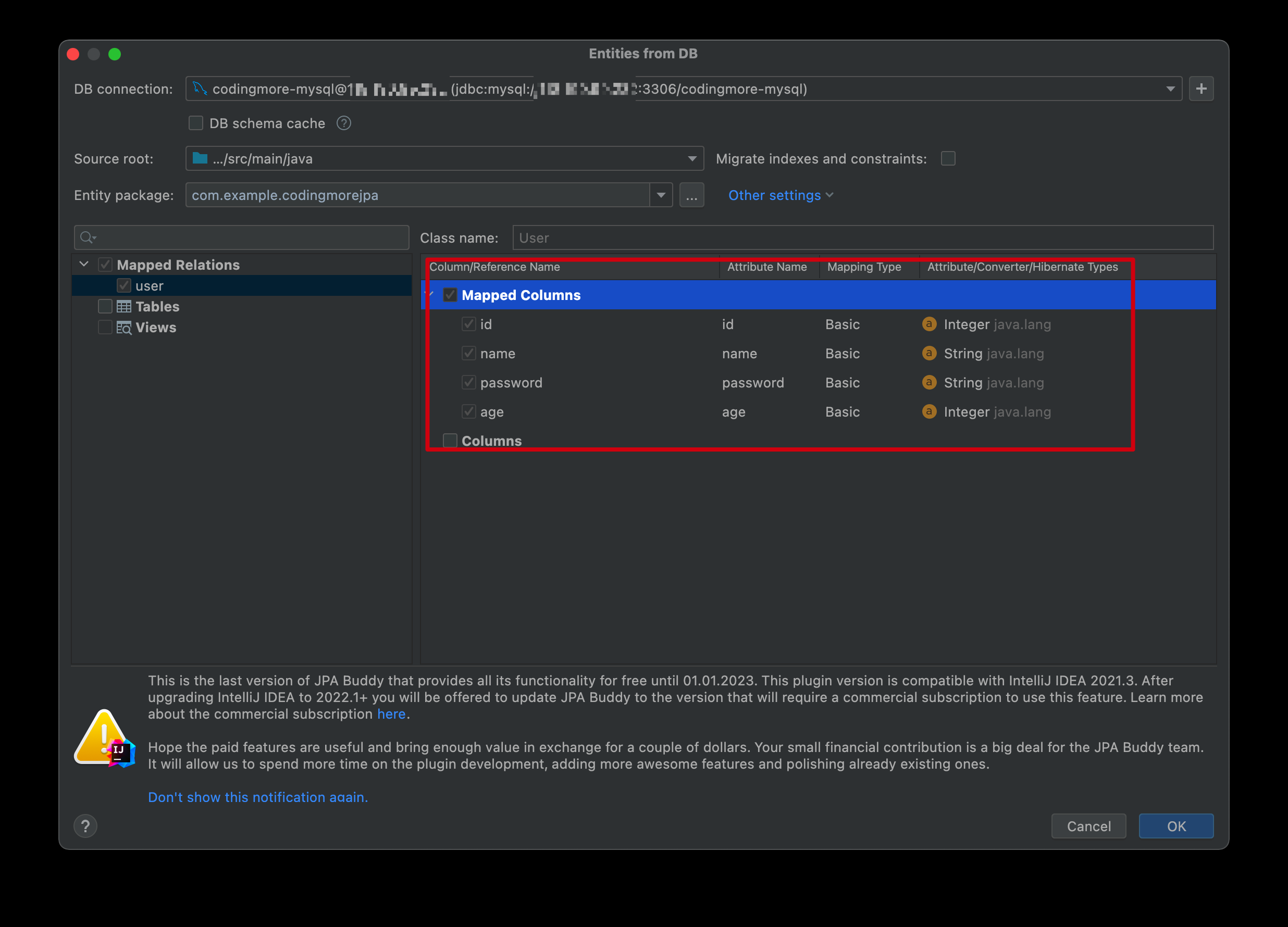
代码如下所示:
@Entity
@Table(name = "user")
public class User {
@Id
@Column(name = "id", nullable = false)
private Integer id;
@Column(name = "name", nullable = false, length = 10)
private String name;
@Column(name = "password", nullable = false, length = 10)
private String password;
@Column(name = "age", nullable = false)
private Integer age;
// 省略 getter/setter
}第四步,新建 UserRepository 接口。
在项目路径上右键,选择新建 JPA Repository。
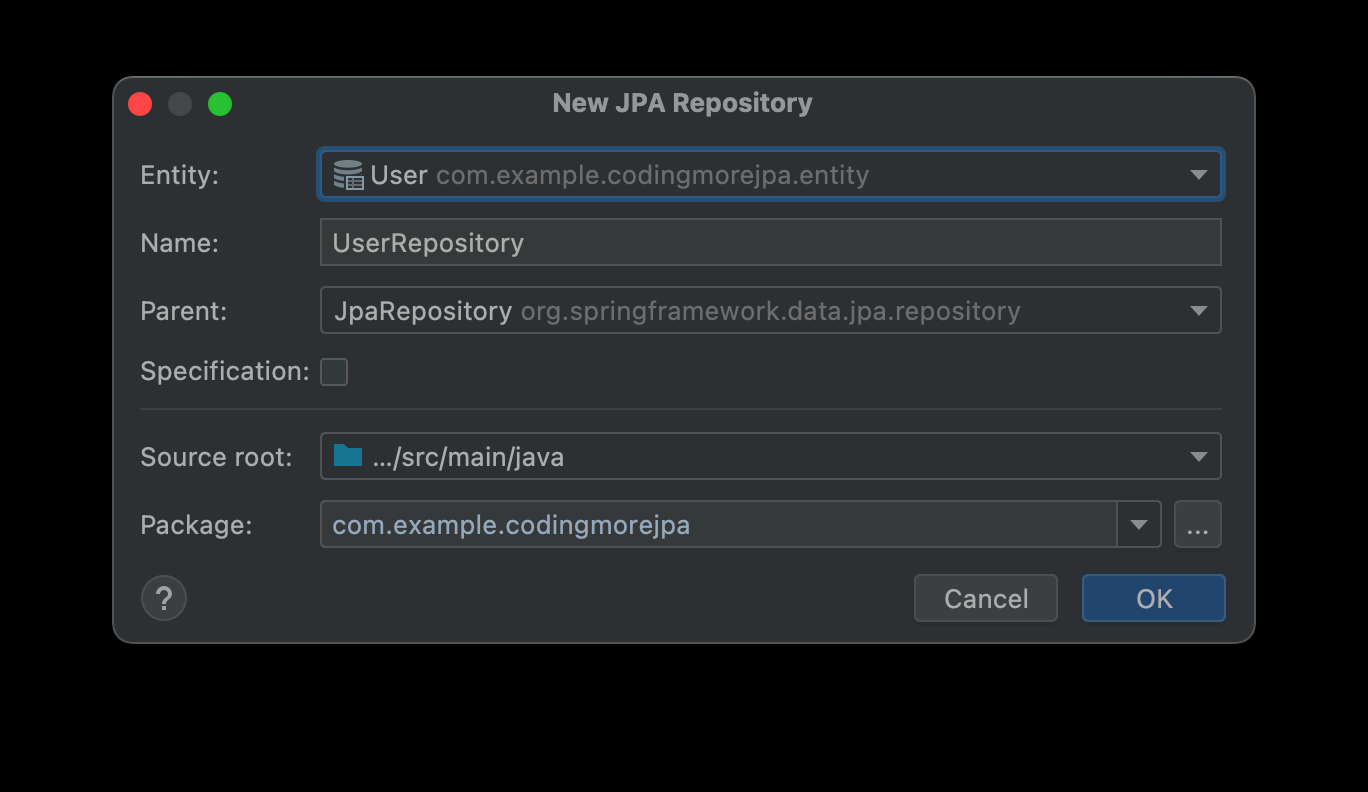
生成的代码如下:
public interface UserRepository extends JpaRepository<User, Integer> {
}如果只是简单的对表进行增删改查操作,那么只需要继承 JpaRepository 接口,并传递两个参数(第一个为实体类,第二个为主键类型)即可。
第五步,新建服务接口 UserService 和实现类 UserServiceImpl。
public interface UserService {
User findById(Integer id);
List<User> findAll();
User save(User user);
void delete(Integer id);
}UserService 定义了 4 个方法:
- findById 根据 ID 查询单条记录
- findAll 查询所有
- save 用来保存和更新
- delete 用来删除
@Service
public class UserServiceImpl implements UserService{
@Resource
private UserRepository userRepository;
@Override
public User findById(Integer id) {
return userRepository.getById(id);
}
@Override
public List<User> findAll() {
return userRepository.findAll();
}
@Override
public User save(User user) {
return userRepository.save(user);
}
@Override
public void delete(Integer id) {
userRepository.deleteById(id);
}
}@Service注解用在服务层,和@Component注解作用类似(通用注解),Spring Boot 会自动扫描该类注解注解的类,并把它们假如到 Spring 容器中。@Resource和@Autowired注解都是用来自动装配对象的,可以用在字段上,也可以用在 setter 方法上。@Autowired 是 Spring 提供的注解,@Resource 是 Java 提供的注解,也就是说,如果项目没有使用 Spring 框架而是 JFinal 框架,@Resource 注解也是支持的。另外,@Resource 是 byName 自动装配,@Autowired 是 byType 自动装配,当有两个类型完全一样的对象时,@Autowired 就会出错了。
苏三写了一篇@Autowired的文章,很不错:https://www.zhihu.com/question/39356740
当然了,只是简单的增删改查已经不能提起我们学习的兴趣了,必须得来点不一样的,所以我们在 UserService 接口中添加一个分页的接口。
Page<User> findAll(Pageable pageable);实现类:
@Override
public Page<User> findAll(Pageable pageable) {
return userRepository.findAll(pageable);
}- Pageable 是 Spring 提供的一个分页查询接口,查询的时候只需要传入一个 Pageable 接口的实现类,指定第几页(pageNumber)和页面大小(pageSize)即可。
- Page 是 Spring 提供的一个分页返回结果接口。
再增加一个自定义查询接口(按照 name 的模糊查询)吧。
首先是 UserRepository,直接用 JPA Buddy 插件:
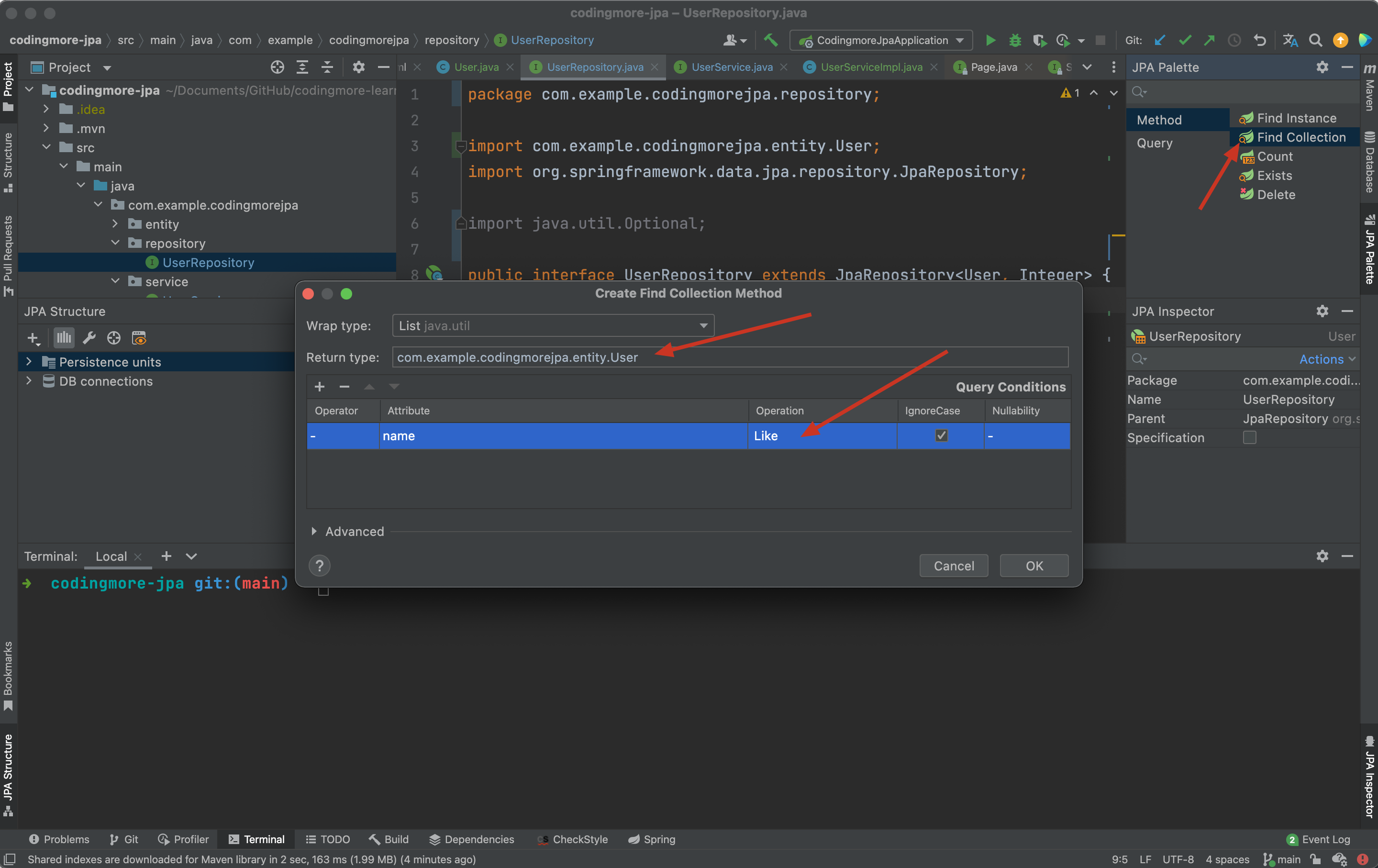
生成的代码如下:
public interface UserRepository extends JpaRepository<User, Integer> {
List<User> findByNameLikeIgnoreCase(String name);
}然后是 UserService 接口:
List<User> findByNameLikeIgnoreCase(String name);最后是 UserServiceImpl:
@Override
public List<User> findByNameLikeIgnoreCase(String name) {
return userRepository.findByNameLikeIgnoreCase(name);
}测试 Spring Data JPA
在测试类中对服务类中的 5 个接口进行测试,顺带在application.yml 中开启 SQL 语句的输出,看看 JPA 自动生成的 SQL 语句到底长什么样子。
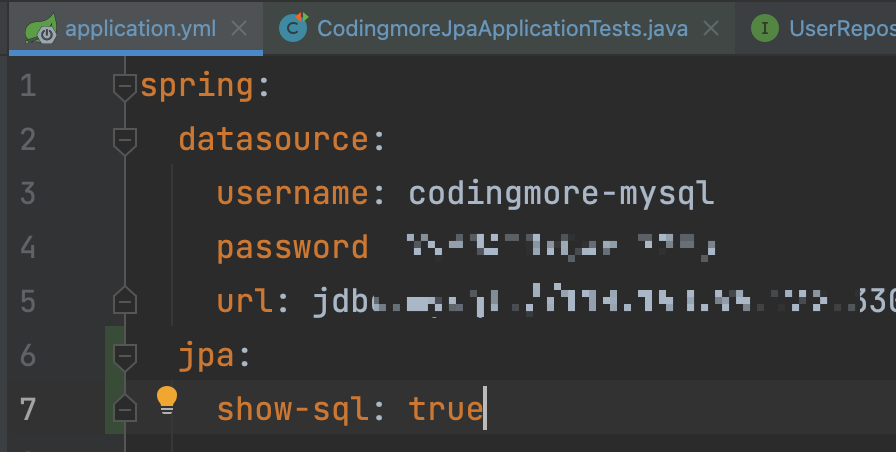
测试类非常简单哈:
@SpringBootTest
@Slf4j
class CodingmoreJpaApplicationTests {
@Resource
private UserService userService;
@Test
void contextLoads() {
// 查询所有
userService.findAll().stream().forEach(user -> log.info("查询所有{}", user));
// 新增数据
userService.save(new User().setId(2).setAge(12).setName("沉默王三").setPassword("123456"));
userService.save(new User().setId(3).setAge(12).setName("沉默王四").setPassword("123456"));
userService.save(new User().setId(4).setAge(12).setName("沉默王五").setPassword("123456"));
// 分页查询
userService.findAll(PageRequest.of(1,2)).stream().forEach(user -> log.info("分页查询{}", user));
// 模糊查询
log.info("模糊查询{}",userService.findByNameLike("沉默"));
// 删除
userService.delete(1);
}
}从日志当中可以看得出,Spring Data JPA 默认使用的是 Hibernate 框架,这是查询全部:
Hibernate: select user0_.id as id1_0_, user0_.age as age2_0_, user0_.name as name3_0_, user0_.password as password4_0_ from user user0_这是保存:
Hibernate: insert into user (age, name, password, id) values (?, ?, ?, ?)这是更新:
Hibernate: update user set age=?, name=?, password=? where id=?这是分页:
Hibernate: select user0_.id as id1_0_, user0_.age as age2_0_, user0_.name as name3_0_, user0_.password as password4_0_ from user user0_ limit ?, ?这是模糊查询:
Hibernate: select user0_.id as id1_0_, user0_.age as age2_0_, user0_.name as name3_0_, user0_.password as password4_0_ from user user0_ where user0_.name like ? escape ?不过,这个模糊查询不符合我们的预期,没有前后的 %,我们可以选择 Spring Data 提供的 @Query 来自定义 SQL 语句。
默认情况下,@Query 注解会使用 JPQL 来进行查询。举个例子:
@Query("select u from User u where u.name like concat('%',?1,'%')")
List<User> findByNameLike(String name);@Query 注解中的 “User” 为实体类的类名,而非数据库的表名 user,这就是 JPQL 和原生 SQL 的区别。来看原生 SQL 的写法:
@Query(value = "SELECT * FROM user u WHERE u.name like '%'|| ?1 || '%'",
nativeQuery = true)
List<User> findByNameLikeNativeQuery(String name);@Query 注解中的 “user” 为数据库表名,另外需要加上参数 nativeQuery,默认值为 false,设为 true 表明开启原生 SQL 查询。注意这次我们用“||”替换了“concat” 方法。
除了使用 ?1、?2 的形式来动态传递参数,我们还可以使用 @Param 注解的形式来传递参数,此时的 SQL 语句中采用 :param 形式来接收参数。
@Query("select u from User u where u.name like concat('%',:name,'%')")
List<User> findByNameLikeParam(@Param("name")String name);这是删除:
Hibernate: delete from user where id=?Spring Data JPA 和 MyBatis 的对比
更多内容,只针对《二哥的Java进阶之路》星球用户开放,需要的小伙伴可以戳链接🔗加入我们的星球,一起学习,一起卷。。编程喵🐱是一个 Spring Boot+Vue 的前后端分离项目,融合了市面上绝大多数流行的技术要点。通过学习实战项目,你可以将所学的知识通过实践进行检验、你可以拓宽自己的技术边界,你可以掌握一个真正的实战项目是如何从 0 到 1 的。
源码地址:
