2025年最新超详细大数据学习路线(建议收藏🔥)
关于大数据
- 1991 年,数据仓库改变诞生
- 2005 年,Hadoop 诞生
- 2010 年,数据湖的概念出现
- 201X 年,大数据平台出现
- 2016 年,阿里提出数据中台的概念
大数据处理框架可以分为:
数据采集:大数据处理的第一步,第一种是通过 Sqoop 或者 Cannal 等工具进行定时抽取或者实时同步;第二种是各种埋点日志,通过 Flume 进行实时收集。
数据存储:大数据处理的第二步,将数据存储到 HDFS 中,实时日志流情况下通过 Kafka 输出给后面的流式计算引擎。
数据分析:大数据的核心环节,包括离线处理和流处理两种方式,对应的计算引擎包括 MapReduce、Spark、Flink 等,处理完的结果会保存到已经提前设计好的数据仓库中,或者 HBase、Redis、RDBMS 等各种存储系统上。
数据应用:数据可视化、工 AI 使用等。
大数据的学习路线
1)语言基础
Java
大数据框架大多采用 Java 语言开发,并且几乎全部的框架都会提供 Java API。
学 Java 的话,不用多说,直接上《二哥的Java进阶之路》网站就 OK 了。
如果想读纸质书的话,推荐《on Java 8》。

Scala
Scala 是一门综合了面向对象和函数式编程概念的静态类型的编程语言,运行在 Java 虚拟机上,可以和 Java 类库无缝衔接,Kafka 就是用 Scala 进行开发的。
为什么要学习 Scala?因为 Flink 和 Spark 都提供了 Scala 接口,使用 Scala 开发,比使用 Java 8 更省代码。另外,spark 就是用 Scala 开发的。
当然了,Scala 不是必学的。也可以放到学完 spark 之后再去学习 Scala。
2)Linux 基础
推荐《鸟哥的私房菜》

或者自己装个 Linux 虚拟机/云服务器直接上手实操。
3)构建工具
Maven,二哥的Java进阶之路上有教程:https://javabetter.cn/maven/maven.html
4)框架学习
- 日志收集框架:Flume、Logstash、Filebeat
- 分布式文件存储系统:Hadoop HDFS
- 数据库系统:Mongodb、HBase
- 分布式计算框架:
- 批处理框架:Hadoop MapReduce
- 流处理框架:Storm
- 混合处理框架:Spark、Flink
- 查询分析框架:Hive 、Spark SQL 、Flink SQL、 Pig、Phoenix
- 集群资源管理器:Hadoop YARN
- 分布式协调服务:Zookeeper
- 数据迁移工具:Sqoop
- 任务调度框架:Azkaban、Oozie
- 集群部署和监控:Ambari、Cloudera Manager
列出的这些主流框架,社区都比较活跃,学习资源也比较丰富。
先学 Hadoop,这是大数据生态圈的基石。
接着学习计算框架,spark 和 flink 是目前最主流的两个混合处理框架。
可以按工作需要学习。
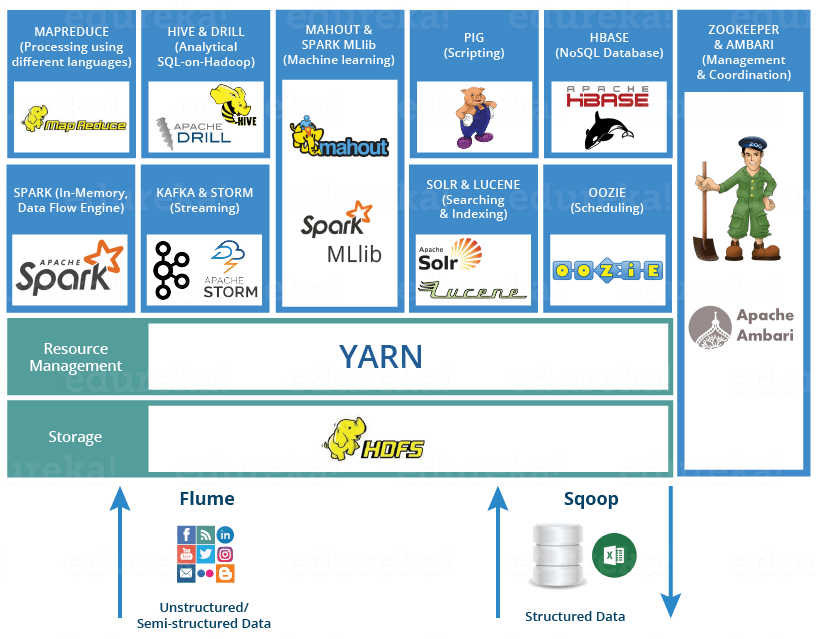
如果学习时间有限的话,初次学习的时候,同一类框架学一种就好。
学习资料最权威和最全面的学习资料就是官方文档,社区也都非常活跃。
这里就列一些优质书籍吧。
- 《hadoop 权威指南 (第四版)》 2017 年
- 《Kafka 权威指南》 2017 年
- 《从 Paxos 到 Zookeeper 分布式一致性原理与实践》 2015 年
- 《Spark 技术内幕 深入解析 Spark 内核架构设计与实现原理》 2015 年
- 《HBase 权威指南》 2012 年
- 《Hive 编程指南》 2013 年
视频的话,尚硅谷的大数据相关视频还不错。
这里还给大家准备了一份 GitHub 上星标 12k 的大数据入门指南,来看一下内容吧。

直接长按识别/扫描下方二维码,关注后回复 「00」 下载这份 PDF 吧:

学习建议
1、Java
这个没毛病,看 二哥的Java进阶之路就好了,Spring Boot 也要能掌握,看星球的《编程喵 🐱 实战项目笔记》就好了。
2、MySQL
要能写复杂的 SQL 语句,为后面学习 Hive 数仓的 HQL 打好基础。
3、Linux
大数据的相关软件都是在 Linux 上运行的,所以 Linux 要学习的扎实一些。
要能在 Linux 上配置 Hadoop、Hive、HBase、Spark 等大数据软件的运行环境和网络环境配置。
4、Hadoop 学习
包括:
- HDFS:存储数据
- MapReduce: 对数据进行处理计算
- Yarn: Yarn 的全称是 Yet Another Resource Negotiator,意思是“另一种资源调度器”,这种命名和“有间客栈”一样,很妙。这里多说一句,以前 Java 有一个项目编译工具,叫做 Ant,他的命名也是类似的,叫做 “Another Neat Tool”的缩写,翻译过来是”另一种整理工具“。
第一步,先让 Hadoop 跑起来
第二步,试着用一用 Hadoop
- 上传下载文件
- 提交运行 MapReduce 示例程序
- 查看 Job 运行状态,查看 Job 运行日志
第三步,了解原理
- MapReduce:如何分而治之
- HDFS:数据到底在哪里,什么是副本
- Yarn 到底是什么,它能干什么;
- NameNode 到底在干些什么;
- esourceManager 到底在干些什么;
第四步,自己写一个 MapReduce 程序
5、学习 Hive
Hive 就是 SQL On Hadoop,Hive 提供了 SQL 接口,开发人员只需要编写简单易上手的 SQL 语句,Hive 负责把 SQL 翻译成 MapReduce,提交运行。
6、学习数据采集
Sqoop 主要用于把 MySQL 里的数据导入到 Hadoop 里的。
Flume 是一个分布式的海量日志采集和传输框架,可以实时的从网络协议、消息系统、文件系统采集日志,并传输到 HDFS 上。
DataX 是阿里云 DataWorks 数据集成的开源版本。
7、学习 Spark
Spark 弥补了 MapReduce 处理数据速度上慢的缺点
8、学习 kafka
使用 Flume 采集的数据,不是直接到 HDFS 上,而是先到 Kafka,Kafka 中的数据可以由多个消费者同时消费,其中一个消费者,就是将数据同步到 HDFS 上。
Flume + Kafka,在实时流式日志的处理非常常见,后面再通过 Spark Streaming 等流式处理技术,就可完成日志的实时解析和应用。
9、学习任务调度 Oozie / Azkaban
10、学习实时数据的处理 Flink / Spark Streaming
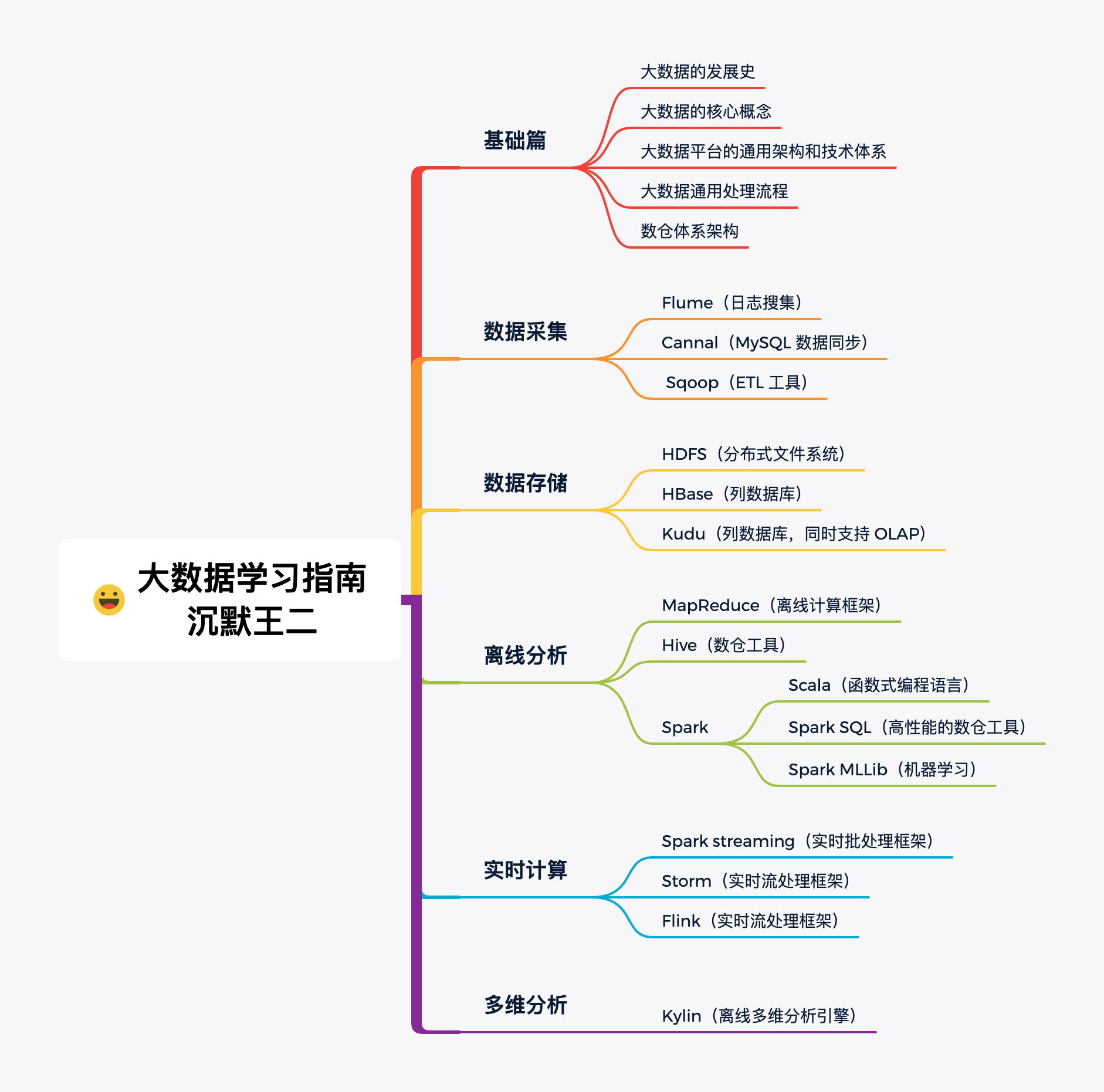
再总结一份大数据学习指南的思维导图吧。
GitHub 上标星 10000+ 的开源知识库《二哥的 Java 进阶之路》第一版 PDF 终于来了!包括Java基础语法、数组&字符串、OOP、集合框架、Java IO、异常处理、Java 新特性、网络编程、NIO、并发编程、JVM等等,共计 32 万余字,500+张手绘图,可以说是通俗易懂、风趣幽默……详情戳:太赞了,GitHub 上标星 10000+ 的 Java 教程
微信搜 沉默王二 或扫描下方二维码关注二哥的原创公众号沉默王二,回复 222 即可免费领取。