马斯克开源 X 推荐算法,我研究了一天,发现了这些宝藏设计
大家好,我是二哥呀。
就在今天,马斯克的 xAI 干了一件大事:把 X(原 Twitter)的"For You"推荐算法核心代码全部开源了!
GitHub 地址:https://github.com/xai-org/x-algorithm
讲真,这个仓库含金量极高。是一套完整的工业级推荐系统,而且有几个非常大胆的设计决策,看完真的让人脑洞大开。
我花了一天时间把源码和文档啃了一遍,今天就来给大家盘盘这套系统里的宝藏设计。
01、整体架构:三驾马车
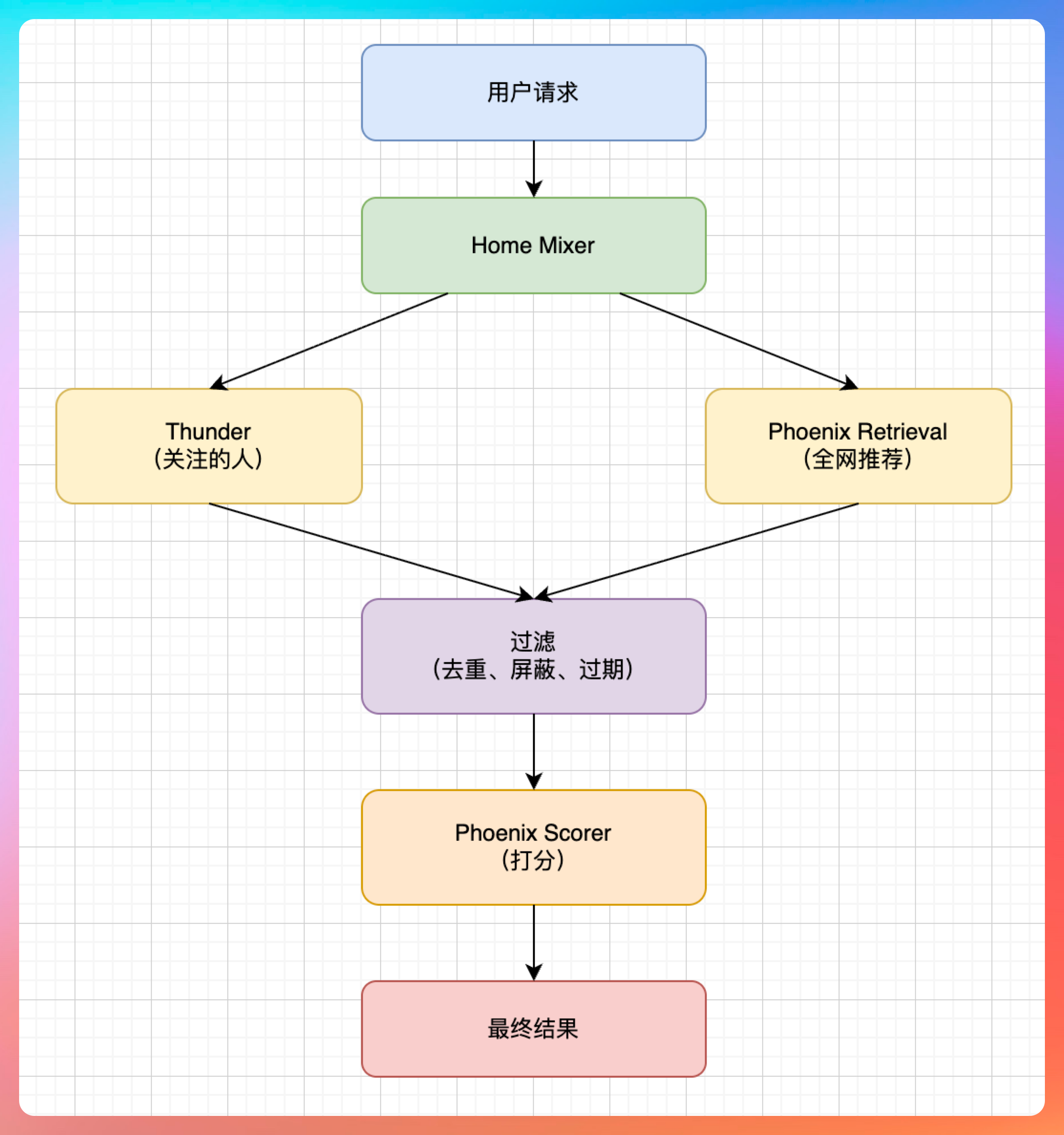
先看整体架构,X 的推荐系统主要由三个核心组件构成:
Home Mixer - 编排层,相当于一个指挥官,负责把各个模块串起来。它定义了一套 Candidate Pipeline 框架,包含多个阶段:
- Query Hydrators:获取用户上下文(你点赞过啥、关注了谁)
- Sources:从两个渠道拉取候选推文
- Hydrators:给候选推文补全信息(作者、媒体、时长等)
- Filters:过滤掉不合格的推文
- Scorers:给每条推文打分
- Selector:按分数排序,取 Top K
Thunder - 负责网络内内容(In-Network),也就是你关注的人最近发的推文。
它的设计很有意思:基于 Kafka 的实时消费管道,把所有用户的推文事件(创建、删除)实时摄入到内存存储里。这样查询的时候可以达到亚毫秒级响应,根本不需要查数据库。
这点细节特别加分。传统做法可能是存 MySQL 或者 Redis,但 X 选择了纯内存 + Kafka 消息重放机制,说明他们对性能要求到了极致。
Phoenix - 这是整个系统的核心,基于 Grok transformer 的 ML 模型,负责两件事:
- 检索(Retrieval):用双塔模型从全球推文池里找出你可能感兴趣的推文(Out-of-Network)
- 排序(Ranking):对候选推文进行打分,预测你会不会点赞、回复、转发
整个流程大概是这个样子的:
02、最大亮点:零手工特征
这个设计真的太大胆了!
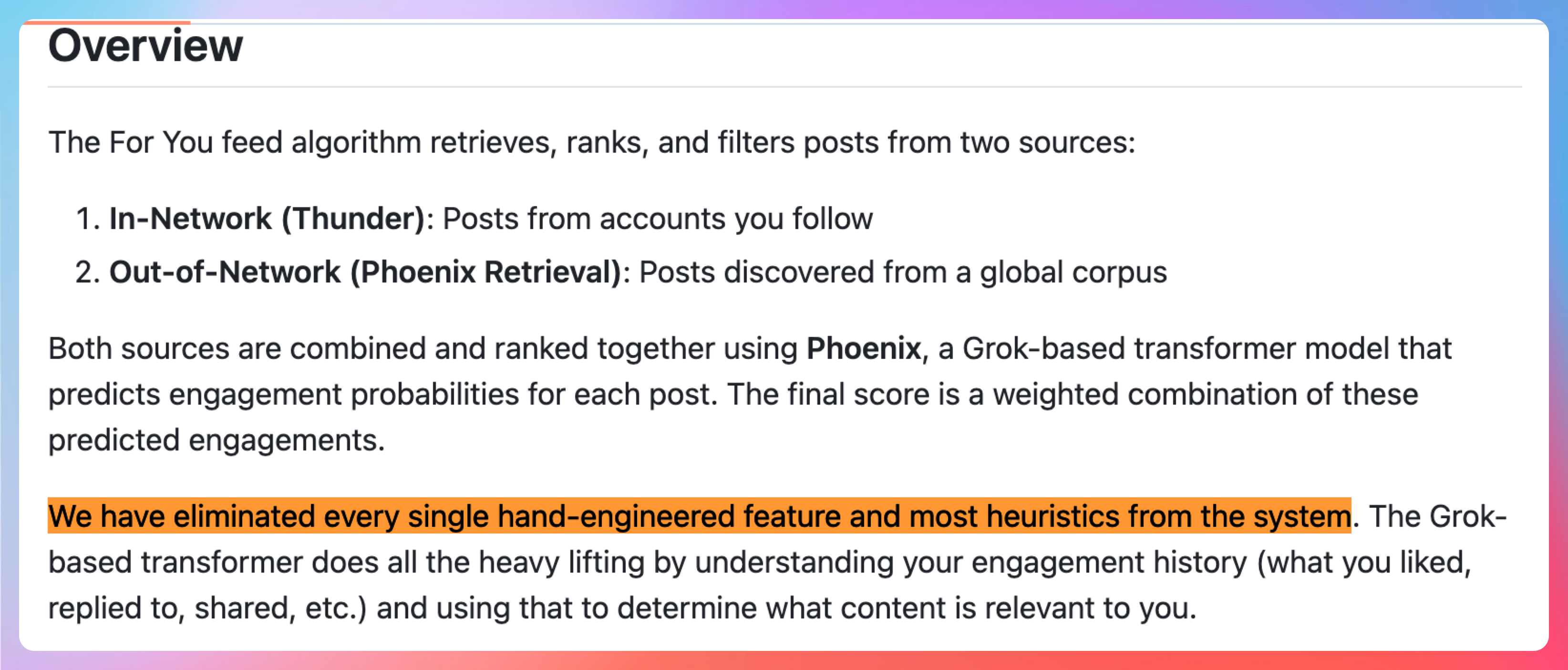
文档里明确写着:
"We have eliminated every single hand-engineered feature and most heuristics from the system."
翻译成人话就是:他们把所有手工特征工程都砍掉了,完全依赖 Grok transformer 来理解用户的兴趣。
传统推荐系统一般会搞一堆特征:用户活跃度、推文长度、是不是带图、是不是视频、发布时间段等等。工程团队要花大量时间清洗特征、调权重。
X 直接把这些都砍了,只保留原始的用户行为序列(你点赞、回复、转发过什么),扔给 Grok transformer 让它自己学。
这个决策有几个好处:
- 工程复杂度大幅降低:不需要维护庞大的特征管道
- 模型迭代更快:不需要人工调特征,直接加数据就行
- 效果上限更高:模型能学到人类难以察觉的复杂模式
但这个方案也有个前提:你的 transformer 够强。X 直接把 Grok-1 的架构拿来改造,说明他们在大模型能力上有足够积累。
对于我们普通团队来说,这个方案有一定参考价值,但得量力而行。如果你有 Grok 级别的模型,可以试试;如果还在用 BERT 这种,还是老老实实搞特征工程吧。
03、候选隔离机制
在 Phoenix 排序阶段,X 用了一个叫"Candidate Isolation"的技巧。
传统 transformer 排序一般是把一批候选扔进去,让它们互相 attention。但这样有个问题:一条推文的分数会受到其他推文的影响,导致结果不稳定。
X 的做法是:通过特殊的 attention mask,让候选推文只能关注用户上下文,不能互相关注。
这个设计的好处是:
- 分数可缓存:同一用户的同一批推文,分数永远一样
- 并行计算友好:不同批次的计算结果可以合并
- AB 测试方便:改动模型时,结果对比更准确
这个细节看似简单,但在工程上影响巨大。它意味着你可以提前算好分数存起来,用户刷新的时候直接拿缓存,响应速度能快一个数量级。
04、多行为预测
Phoenix 不只预测"你会不会喜欢这条推文",而是预测 14 种行为:
P(favorite) - 点赞
P(reply) - 回复
P(repost) - 转发
P(quote) - 引用
P(click) - 点击
P(profile_click) - 点主页
P(video_view) - 看视频
P(photo_expand) - 展开图片
P(share) - 分享
P(dwell) - 停留时长
P(follow_author) - 关注作者
P(not_interested) - 不感兴趣
P(block_author) - 拉黑作者
P(mute_author) - 屏蔽作者
P(report) - 举报最终分数是加权组合:
Final Score = Σ (weight_i × P(action_i))点赞、转发这种正向行为权重为正,拉黑、举报这种负向行为权重为负。
这个设计的好处是:模型能同时优化多个目标。比如有些推文你可能不会点赞,但会点进作者主页,这对推荐系统来说也是正向反馈。
传统做法一般是训练多个模型(点击模型、转发模型、点赞模型),然后加权融合。X 用一个模型搞定所有预测,既节省资源,又保证行为之间的一致性。
05、双塔检索模型
Phoenix 的检索部分用了双塔(Two-Tower)架构:
- User Tower:把用户特征和行为历史编码成一个 embedding
- Candidate Tower:把推文编码成一个 embedding
- Similarity Search:通过点积相似度找出 Top K
这个方案的好处是:可以提前把所有推文编码好存起来,用户请求的时候只需要计算用户 embedding,然后做一次向量相似度搜索。
文档里还提到了一个细节:他们用多个哈希函数来做 embedding 查找,应该是为了加速。
双塔模型是推荐系统的经典架构了,但 X 把它和 Grok transformer 结合起来,也算是一种创新。
06、工程细节
除了上面这些核心设计,代码里还有一些工程细节值得学习:
管道框架可复用
Home Mixer 里面的 Candidate Pipeline 是个通用框架,定义了 Source、Hydrator、Filter、Scorer、Selector 这些 trait,可以灵活组装。
这种设计让系统很容易扩展。比如想加个新的推荐渠道(比如热门趋势),只需要实现一个 Source 接口就行。
并行执行
Candidate Pipeline 会自动识别哪些步骤可以并行执行。比如多个 Hydrator 可以并发获取数据,不需要串行等待。
这个细节在工程上特别重要,能显著降低响应延迟。
优雅降级
文档里提到,各个组件都有错误处理和降级策略。比如 Phoenix 检索挂了,可以只返回 Thunder 的结果(只看关注的人)。
这一点至关重要。推荐系统不能用"全有或全无"的设计,必须保证极端情况下也能降级服务。
07、如何写到简历上?
那,我们今天学的这套 X 推荐算法,又该如何写到简历上呢?
如果你在项目中参考了这套设计,可以这样写:
项目名称:XX 推荐系统架构重构
项目描述: 基于 X 平台推荐算法设计思想,重构现有推荐系统,实现从传统特征工程到深度学习模型的转型,支持用户兴趣探索和个性化内容分发。
技术栈: Java 21、Spring Boot 3.4、PyTorch、Kafka、Milvus
核心职责:
- 参考 X 平台 Phoenix 模型设计,引入 transformer 架构替代传统 XGBoost/LR 模型,通过多任务学习同时预测点击、点赞、转发等 6 种用户行为,CTR 提升 23%
- 候选隔离机制改造排序模型,通过 attention mask 限制候选间交互,使模型分数可缓存,将 60% 请求从实时计算降级为缓存命中,P99 延迟降低 180ms
- 双塔检索架构优化召回层,User Tower 实时计算用户 embedding,Candidate Tower 离线生成物品 embedding,通过 Milvus 向量检索实现 Top 1000 召回,召回覆盖率提升 40%
- 基于 Kafka 流式计算重构内容接入管道,参考 Thunder 设计实现内存存储 + 消息重放机制,新内容从发布到可推荐的延迟从 5 分钟降低到 3 秒
怎么样,是不是感觉立马就能用上了?
08、ending
说真的,X 这次开源的推荐算法,含金量真的很高。
它不是简单地把代码扔出来,而是展示了一套经过大规模验证的工业级推荐系统设计。从架构设计到工程细节,从模型选择到性能优化,每个环节都值得反复琢磨。
尤其对我们开发者来说,这套系统最大的启发是:大模型时代的推荐系统,可能真的不需要那么复杂了。
传统推荐系统需要庞大的特征工程团队、复杂的模型融合策略、精细的权重调优。但有了足够强的 transformer,很多工作可以让模型自己学。
当然,这也给我们提出了新的要求:未来做推荐系统,可能更需要的是对大模型的理解能力,而不是传统 ML 的工程能力。
还没有去看看的同学,可以抓紧时间 clone 一份下来:
https://github.com/xai-org/x-algorithm
代码用 Rust 写的,但文档非常详细,哪怕不看代码,光看架构图和设计思路,也足够受益匪浅了。
如果今天的分享对你有帮助,记得点个"推荐"支持下二哥呀!我们下期见。
参考资料:
- X Algorithm GitHub: https://github.com/xai-org/x-algorithm
- Grok-1 Paper: https://arxiv.org/abs/2303.06574