一文带你看懂,火爆全网的Skills到底是啥(附TRAE+Java源码实战)
大家好,我是二哥呀。
最近这段时间,AI圈子里最火的概念莫过于 Claude Skills 了。GitHub上anthropics/skills仓库短短几个月就冲到了47.5k+星,开发者社区到处都在讨论这个"给Agent插上翅膀"的新玩法。
说真的,刚接触Skills的时候我有点不理解。这不就是Prompt工程的封装吗?但深入研究后发现,这玩意儿的设计理念确实有点东西,尤其是渐进式披露机制,直接解决了大模型token浪费的痛点。
今天这篇文章,我就带你彻底搞懂:
- Skills到底是什么,为什么这么火
- Skills的渐进式加载原理和调用逻辑
- Skills和MCP到底有啥区别
- 官方推荐的Skills有哪些好用的
- 如何在TRAE中创建自己的Skills
- 最后,我们还会自己动手实现一个类似Claude Skills的机制
好,我们直接开始。
01、Claude Skills是个啥?
用一句话概括:Skills是Claude的"专业技能包",通过预定义的工作流程和指令,让Claude在特定领域变得更专业。
你可以把它理解为:
- MCP是Claude的"手和脚"(连接外部工具)
- Skills是Claude的"大脑工作流"(规定做事方法)
举个具体的例子。
假设你想让Claude帮你写Spring Boot技术文章。没有Skills的时候,你可能每次都要这样对话:
用户:帮我写一篇Spring Boot的文章
Claude:好的,什么主题?
用户:Spring Boot 4.x的新特性
Claude:好,请问目标读者是谁?字数多少?什么风格?
用户:Java开发者,3000字,二哥那种通俗易懂的风格...有了Skills之后,这些"写作规范"就打包成了一个ai-article Skill。你只需要说:
用户:用ai-article技能写一篇Spring Boot 4.x新特性的文章Claude会自动加载整个Skill定义,按照预定的流程、风格、格式来完成文章。是不是爽歪歪?
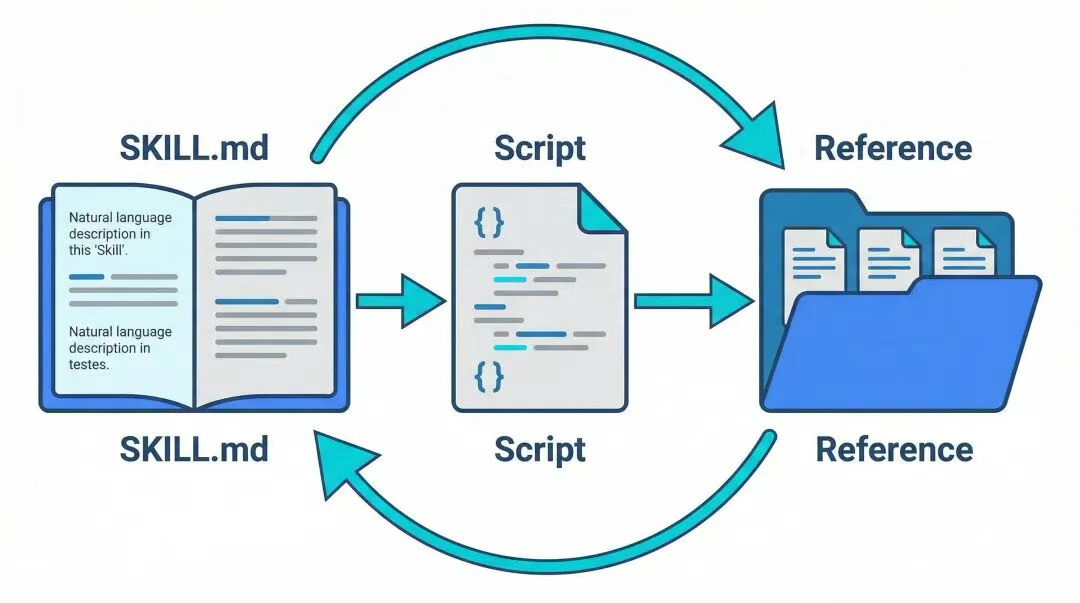
从技术角度看,一个Skill就是一个文件夹,里面包含:
SKILL.md- 核心定义文件(描述、触发条件、执行流程)sample/- 参考示例tools/- 自定义工具(可选)
02、Skills的核心原理:渐进式披露
这是Skills最精彩的设计。
大家知道,大模型的上下文窗口是有限资源,比如说Claude Sonnet 4.5的上下文长度是200k tokens。如果每次对话都把所有Skills的完整定义塞进去,那不是浪费吗?
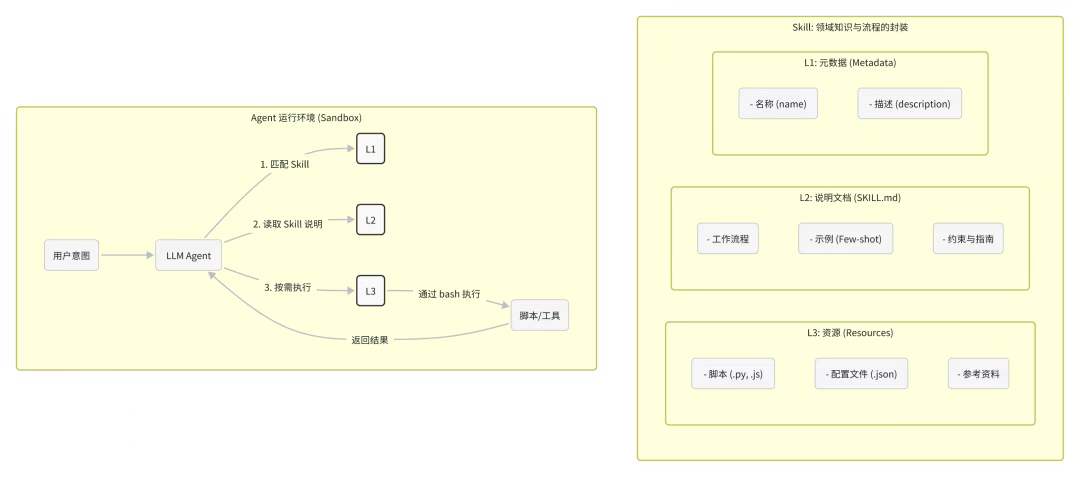
Anthropic的工程师设计了一套三层渐进式加载机制:
第一层:元数据预加载
Claude Code启动时,只会把每个Skill的名称和简短描述加载到system prompt中。
比如你有20个Skills,可能只占几百个tokens,Claude就知道"哦,我现在有这些能力可用"。
## Available Skills
- ai-article: 按照二哥风格撰写AI技术文章
- qiuzhi: 按照二哥风格撰写求职类文章
- commit: 创建符合规范的Git提交信息
- pdf: 处理PDF文件的提取、合并、表单填写
...第二层:按需完整加载
当你的请求触发了某个Skill的描述时,Claude才会去加载完整的SKILL.md文件。
触发判断是自动的,不需要你手动调用。Claude会根据语义匹配来判断"这个请求应该用哪个Skill"。
比如你说"写一篇AI文章",Claude发现这和ai-article的描述高度匹配,就会:
- 读取完整的
SKILL.md - 按照里面定义的工作流程执行
- 完成任务后释放上下文
第三层:参考文档懒加载
有些Skill可能包含大量的参考资料(比如我的ai-article Skill里有完整的写作指南)。这些内容可以放在单独的文件中,只有真正需要时才读取。
调用逻辑流程
整个调用过程是这样的:
用户请求
↓
Claude分析请求语义
↓
匹配Skills元数据(第一层)
↓
判断是否需要加载完整Skill
↓
加载SKILL.md(第二层)
↓
按照Skill定义的流程执行
↓
返回结果这个设计带来的好处:
- 节省token:不用的Skill不加载
- 提高响应速度:减少上下文干扰
- 自动发现:Claude自己判断用哪个Skill,无需手动指定
03、Skills vs MCP
这是很多人容易混淆的地方。我先给你一张对比表:
| 维度 | MCP | Skills |
|---|---|---|
| 定位 | 桥梁协议 | 任务执行模块 |
| 功能 | 连接外部系统(数据库、API、浏览器等) | 封装工作流程和指令 |
| 比喻 | "大模型的手和脚" | "大模型的大脑工作流" |
| 使用方式 | 需要配置服务器或本地服务 | 按需加载,像插件一样 |
| 开发门槛 | 高,需要开发MCP Server | 低,写Markdown文件即可 |
| 适用场景 | 需要访问外部数据源 | 标准化重复性任务 |
一句话区分
MCP让Claude能"碰到"外部工具,Skills让Claude会"使用"工作流执行特定任务。
举个例子:
- 你想让Claude操作Chrome浏览器自动化测试 → 用Playwright MCP
- 你想让Claude按照特定规范写代码注释 → 用Skills
为什么有了MCP还需要Skills?
三个原因:
- Skills更易用,MCP需要搭建Server,Skills只需要写Markdown,普通用户也能快速创建自己的Skill
- 互补而非替代,MCP提供工具连接能力,Skills提供标准化工作流,两者可以结合使用:一个Skill可以调用MCP工具
- 更省token,Skill的元数据描述比MCP工具描述更简洁,渐进式加载机制避免一次性加载过多内容
04、如何写好一个Skill?
写Skill其实就是在写"超级Prompt",但有几个关键点需要注意。
Skill的基本结构
# [Skill名称]
## 描述
一句话说明这个Skill做什么,用于Claude自动匹配
## 触发条件
哪些场景下应该使用这个Skill
## 工作流程
1. 步骤一
2. 步骤二
3. 步骤三
## 输出格式
规定输出的样式、格式、风格
## 注意事项
- 重要事项1
- 重要事项2写好Skill的5个原则
1. 描述要精准
❌ 坏例子:写文章的Skill
✅ 好例子:按照二哥风格撰写AI技术类文章,字数2000-3000字,语气通俗易懂2. 流程要清晰 不要让Claude自己"发挥",把每个步骤写清楚:
## 工作流程
1. 确认当前日期(使用date命令)
2. 判断文章类型(AI技术类/求职类)
3. 读取对应的写作指南
4. 搜集相关资料
5. 按照模板撰写文章
6. 保存到指定目录3. 提供参考示例 在sample/目录下放一些成功案例,让Claude学习风格。
这个是最关键的,直接影响输出质量。
4. 定义明确的输出格式
## 输出格式
---
title: 文章标题
shortTitle: 短标题
description: 文章描述
tag:
- 标签1
- 标签2
category:
- 技术文章
author: 二哥
date: YYYY-MM-DD
---
正文内容...5. 加入质量检查清单
## 质量检查
- [ ] 开头是否用"大家好,我是二哥呀。"
- [ ] 是否用"你"称呼读者
- [ ] 正文是否用"## 01、标题"格式
...05、Claude官方Skills推荐
Anthropic在GitHub上开源了官方Skills仓库,包含20+个实用技能。我给你挑几个最实用的:
必装Top 5
1. skill-creator
- 功能:创建和管理其他Skills的元工具
- 使用场景:你要自己写Skill时必装
- 安装:
git clone https://github.com/anthropics/skills.git
2. commit
- 功能:自动创建符合规范的Git提交信息
- 特点:自动分析改动、生成多行提交信息、遵循Co-Authored-By规范
- 使用:直接说"帮我提交这些改动"即可
3. pdf
- 功能:PDF文件的提取、合并、拆分、表单填写
- 特点:处理中文PDF效果好、保留格式
- 使用场景:处理文档、报表、合同等
4. docx
- 功能:Word文档的创建、编辑、修订模式
- 特点:支持追踪修改、批注、格式保留
- 使用场景:协作文档、报告生成
5. frontend-design
- 功能:创建生产级前端界面
- 特点:使用React、Tailwind CSS、shadcn/ui
- 使用场景:快速原型、Landing Page、Dashboard
其他实用Skills
- pptx:演示文稿创建和编辑
- xlsx:Excel表格处理、公式计算
- mcp-builder:构建MCP服务器
- slack-gif-creator:创建Slack动画GIF
- canvas-design:创建.png和.pdf格式的视觉设计
社区Awesome列表
GitHub上有一些社区维护的Skills集合,比如:
- awesome-claude-skills:收集社区最佳实践
- claude-skills-examples:各种场景的Skill示例
建议新手从官方Skills开始,熟悉机制后再自己写。
06、在TRAE中创建Skills实战
TRAE是国内的一款AI IDE,也支持Skills功能。我手把手教你创建一个。
前置准备
- 下载安装TRAE IDE(https://docs.trae.cn/)
- 确保版本是最新的
手动创建Skill
如果你想自己定义Skill,可以这样做:
Step 1:创建Skill文件夹
mkdir -p ~/trae-skills/my-java-skill
cd ~/trae-skills/my-java-skillStep 2:编写SKILL.md
# Java Code Review Skill
## 描述
按照阿里巴巴Java开发手册规范进行代码审查
## 触发条件
用户请求代码审查、代码优化建议、遵循Java编码规范
## 审查流程
1. 读取待审查的Java代码
2. 检查命名规范(类名、方法名、变量名)
3. 检查注释规范(类注释、方法注释、行注释)
4. 检查异常处理(避免吞异常、异常信息要具体)
5. 检查资源管理(IO流、数据库连接要关闭)
6. 检查并发安全(线程安全、锁的使用)
7. 输出审查报告
## 输出格式
### 代码审查报告
**文件**: xxx.java
**问题列表**:
1. [严重] 类命名不规范:`test` 应改为 `Test`
2. [一般] 缺少方法注释
3. [建议] 使用try-with-resources管理流
**评分**: 7/10
**修改建议**:
[具体代码示例]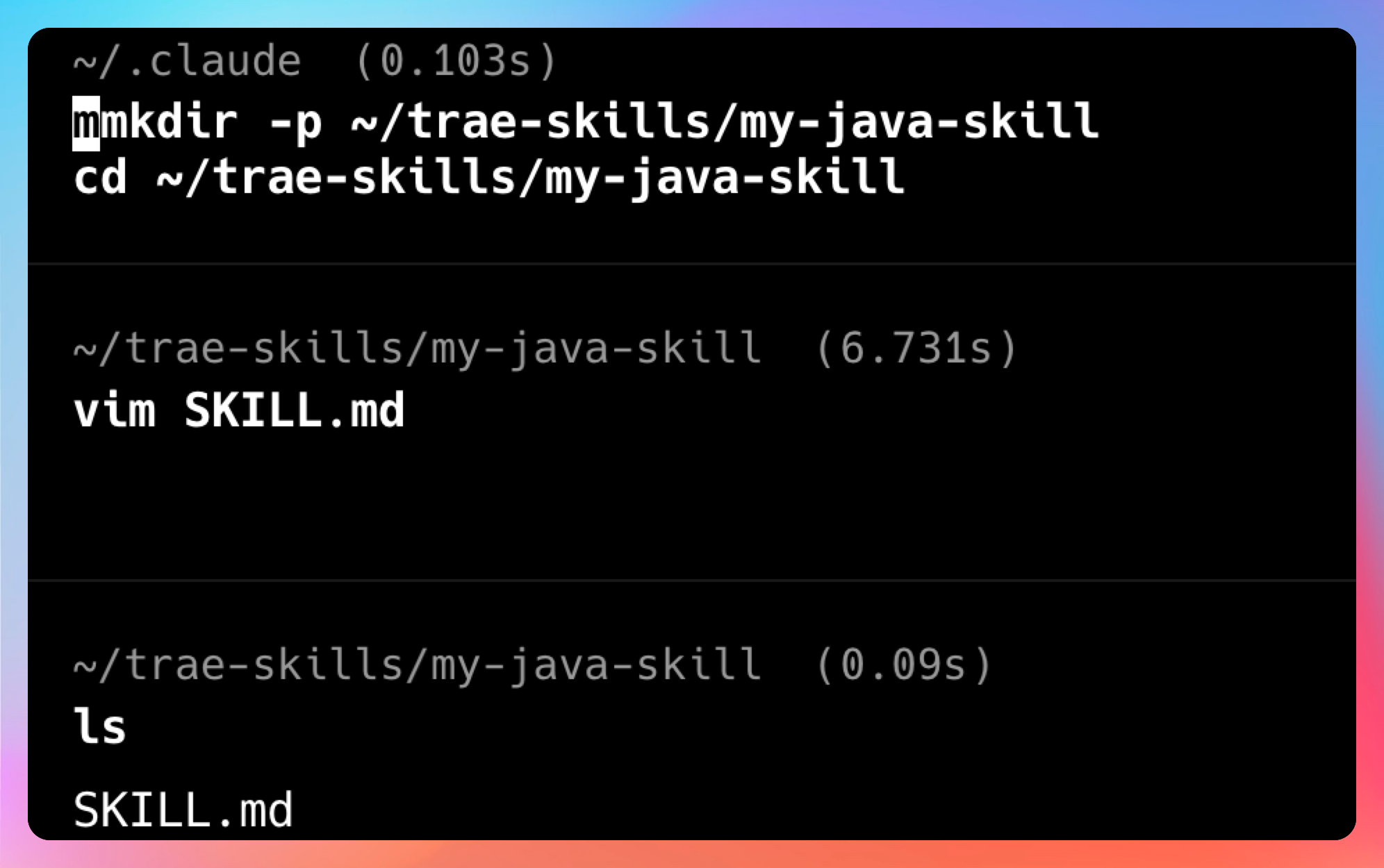
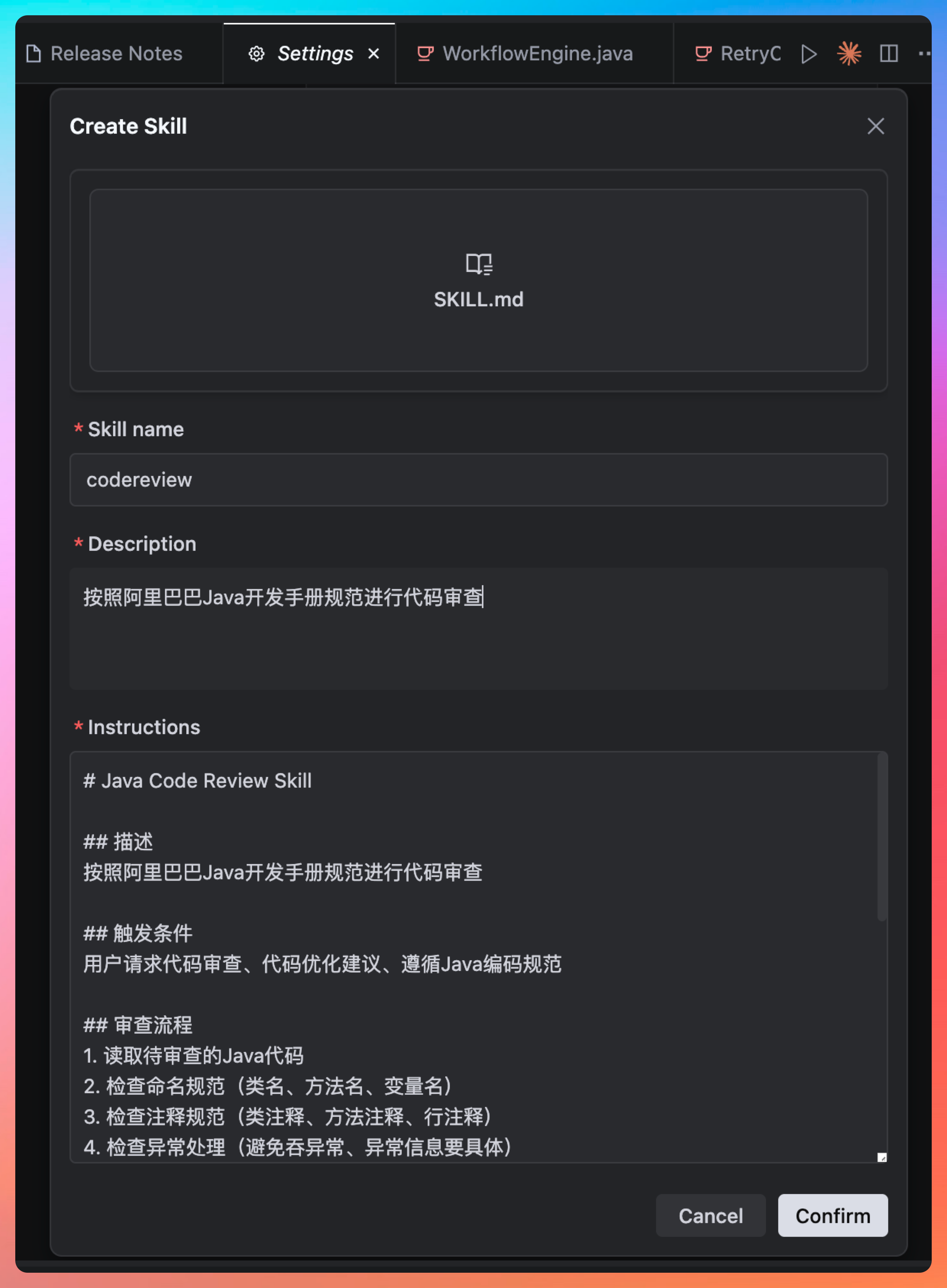
Step 3:在TRAE中导入
- 打开Skills管理界面
- 点击"导入本地Skill"
- 选择
my-java-skill文件夹 - 确认导入
Step 4:测试使用 在TRAE的solo模式下输入:
帮我审查一下这个类
[粘贴你的Java代码]
就可以看到TRAE加载了 codereview 这个Skills。
07、自己动手实现一个Skills系统
如果你想深入理解Skills的原理,最好的方式就是自己实现一个。我们用Java来做一个简单的Skills系统。
项目结构
myskills/
├── skills/ # Skills存放目录
│ ├── ai-article/
│ │ └── SKILL.md
│ └── git-commit/
│ └── SKILL.md
├── src/main/java/
│ └── com/claude/skills/
│ ├── SkillLoader.java # Skill加载器
│ ├── SkillMatcher.java # Skill匹配器
│ ├── MySkills.java # 主程序
│ └── Main.java # 入口类
└── pom.xml # Maven配置核心代码实现
SkillLoader.java - 渐进式加载
/**
* Skills加载器 - 实现三层渐进式披露机制
*/
public class SkillLoader {
/**
* Skill元数据类
*/
public static class SkillMetadata {
private final String description;
private final List<String> triggerConditions;
public SkillMetadata(String description, List<String> triggerConditions) {
this.description = description;
this.triggerConditions = triggerConditions;
}
public String getDescription() {
return description;
}
public List<String> getTriggerConditions() {
return triggerConditions;
}
}
private final String skillsDir;
// 第一层缓存:元数据缓存(启动时加载)
private final Map<String, SkillMetadata> metadataCache = new ConcurrentHashMap<>();
// 第二层缓存:完整Skill缓存(按需加载)
private final Map<String, String> fullSkillCache = new ConcurrentHashMap<>();
public SkillLoader(String skillsDir) {
this.skillsDir = skillsDir;
}
/**
* 第一层:加载所有Skills的元数据
* 只读取名称、描述和触发条件,节省token
*/
public Map<String, SkillMetadata> loadMetadata() throws IOException {
if (!metadataCache.isEmpty()) {
return metadataCache;
}
Path skillsPath = Paths.get(skillsDir);
if (!Files.exists(skillsPath)) {
throw new IOException("Skills目录不存在: " + skillsDir);
}
// 遍历所有Skill目录
Files.list(skillsPath)
.filter(Files::isDirectory)
.forEach(skillDir -> {
String skillName = skillDir.getFileName().toString();
Path skillFile = skillDir.resolve("SKILL.md");
if (Files.exists(skillFile)) {
try {
List<String> lines = Files.readAllLines(skillFile);
SkillMetadata metadata = extractMetadata(lines);
metadataCache.put(skillName, metadata);
} catch (IOException e) {
System.err.println("读取Skill失败: " + skillName);
}
}
});
return metadataCache;
}
/**
* 第二层:按需加载完整Skill
* 只在真正需要时才加载完整内容
*/
public String loadFullSkill(String skillName) throws IOException {
// 检查缓存
if (fullSkillCache.containsKey(skillName)) {
return fullSkillCache.get(skillName);
}
Path skillPath = Paths.get(skillsDir, skillName, "SKILL.md");
if (!Files.exists(skillPath)) {
throw new FileNotFoundException("Skill not found: " + skillName);
}
String content = Files.readString(skillPath);
fullSkillCache.put(skillName, content);
return content;
}
/**
* 从SKILL.md中提取元数据(描述和触发条件)
*/
private SkillMetadata extractMetadata(List<String> lines) {
String description = "无描述";
List<String> triggerConditions = new java.util.ArrayList<>();
boolean inTriggerSection = false;
for (int i = 0; i < lines.size(); i++) {
String line = lines.get(i).trim();
// 提取描述
if (line.startsWith("## 描述")) {
if (i + 1 < lines.size()) {
description = lines.get(i + 1).trim();
}
}
// 提取触发条件
if (line.startsWith("## 触发条件")) {
inTriggerSection = true;
continue;
}
// 触发条件section结束
if (inTriggerSection && line.startsWith("##")) {
inTriggerSection = false;
}
// 读取触发条件列表项
if (inTriggerSection && line.startsWith("-")) {
String condition = line.substring(1).trim();
if (!condition.isEmpty()) {
triggerConditions.add(condition);
}
}
}
return new SkillMetadata(description, triggerConditions);
}
/**
* 从SKILL.md中提取描述
*/
private String extractDescription(List<String> lines) {
for (int i = 0; i < lines.size(); i++) {
if (lines.get(i).startsWith("## 描述")) {
// 获取下一行
if (i + 1 < lines.size()) {
return lines.get(i + 1).trim();
}
}
}
return "无描述";
}
/**
* 生成包含元数据的system prompt
*/
public String getSystemPrompt() throws IOException {
Map<String, SkillMetadata> metadata = loadMetadata();
StringBuilder prompt = new StringBuilder("## Available Skills\n\n");
metadata.forEach((name, meta) ->
prompt.append("- ").append(name).append(": ").append(meta.getDescription()).append("\n")
);
return prompt.toString();
}
/**
* 清除缓存(用于测试或重新加载)
*/
public void clearCache() {
metadataCache.clear();
fullSkillCache.clear();
}
}SkillMatcher.java - 语义匹配
/**
* Skills匹配器 - 根据用户输入匹配合适的Skill
*/
public class SkillMatcher {
private final SkillLoader loader;
public SkillMatcher(SkillLoader loader) {
this.loader = loader;
}
/**
* 根据用户输入匹配合适的Skill
* 返回匹配分数最高的Skill名称
*/
public Optional<String> matchSkill(String userInput) throws IOException {
Map<String, SkillLoader.SkillMetadata> metadata = loader.loadMetadata();
// 简单的关键词匹配(实际应该用语义相似度算法)
String bestMatch = null;
double bestScore = 0.0;
for (Map.Entry<String, SkillLoader.SkillMetadata> entry : metadata.entrySet()) {
String skillName = entry.getKey();
SkillLoader.SkillMetadata meta = entry.getValue();
double score = calculateScore(userInput, meta);
if (score > bestScore) {
bestScore = score;
bestMatch = skillName;
}
}
// 设置阈值,低于0.3认为没有匹配的Skill
if (bestScore > 0.3) {
return Optional.of(bestMatch);
}
return Optional.empty();
}
/**
* 计算匹配分数
* 优先匹配触发条件,其次匹配描述
*/
private double calculateScore(String userInput, SkillLoader.SkillMetadata metadata) {
double triggerScore = calculateTriggerScore(userInput, metadata.getTriggerConditions());
double descScore = calculateDescriptionScore(userInput, metadata.getDescription());
// 触发条件权重更高
return triggerScore * 0.7 + descScore * 0.3;
}
/**
* 计算触发条件匹配分数
*/
private double calculateTriggerScore(String userInput, List<String> triggerConditions) {
if (triggerConditions.isEmpty()) {
return 0.0;
}
int matchCount = 0;
for (String condition : triggerConditions) {
// 提取条件中的关键词(处理"用户提到"AI文章"、"技术文章""这种格式)
if (condition.contains("用户提到") || condition.contains("包含") || condition.contains("涉及")) {
// 提取引号中的关键词
List<String> keywords = extractKeywords(condition);
for (String keyword : keywords) {
if (userInput.contains(keyword)) {
matchCount++;
break; // 一个条件匹配上就算
}
}
} else {
// 直接包含匹配
if (userInput.contains(condition)) {
matchCount++;
}
}
}
return (double) matchCount / triggerConditions.size();
}
/**
* 从条件描述中提取关键词(引号中的内容)
*/
private List<String> extractKeywords(String condition) {
List<String> keywords = new java.util.ArrayList<>();
// 匹配中文引号和英文引号
String[] parts = condition.split("[\"\"「」『』]");
for (int i = 0; i < parts.length; i++) {
String part = parts[i].trim();
// 引号中的内容通常在奇数索引位置
if (!part.isEmpty() && i % 2 == 1) {
keywords.add(part);
}
}
// 如果没有引号,按逗号、顿号分割
if (keywords.isEmpty()) {
String[] tokens = condition.split("[,,、]");
for (String token : tokens) {
String cleaned = token.trim();
if (!cleaned.isEmpty() && !cleaned.contains("用户") && !cleaned.contains("包含")) {
keywords.add(cleaned);
}
}
}
return keywords;
}
/**
* 计算描述匹配分数(原有的简化版算法)
*/
private double calculateDescriptionScore(String userInput, String description) {
// 将输入转为小写并分词
Set<String> userWords = Arrays.stream(userInput.toLowerCase().split("\\s+"))
.filter(word -> !word.isEmpty())
.collect(Collectors.toSet());
Set<String> descWords = Arrays.stream(description.toLowerCase().split("\\s+"))
.filter(word -> !word.isEmpty())
.collect(Collectors.toSet());
if (userWords.isEmpty()) {
return 0.0;
}
// 计算交集比例
Set<String> intersection = new HashSet<>(userWords);
intersection.retainAll(descWords);
return (double) intersection.size() / userWords.size();
}
}MySkills.java - 主程序
/**
* Skills系统主程序
*/
public class MySkills {
private final SkillLoader loader;
private final SkillMatcher matcher;
private final Scanner scanner;
public MySkills(String skillsDir) {
this.loader = new SkillLoader(skillsDir);
this.matcher = new SkillMatcher(loader);
this.scanner = new Scanner(System.in);
}
/**
* 处理用户输入
*/
public String process(String userInput) {
try {
// 1. 匹配Skill
Optional<String> skillNameOpt = matcher.matchSkill(userInput);
if (skillNameOpt.isEmpty()) {
return "抱歉,我没有找到合适的Skill来处理这个请求。";
}
String skillName = skillNameOpt.get();
// 2. 加载完整Skill
String skillContent = loader.loadFullSkill(skillName);
// 3. 这里应该调用LLM API,将Skill内容作为system prompt
// 简化版:直接返回Skill内容
return "【使用Skill: " + skillName + "】\n\n" + skillContent;
} catch (IOException e) {
return "处理请求时出错: " + e.getMessage();
}
}
/**
* 显示所有可用的Skills
*/
public void showAvailableSkills() {
try {
Map<String, SkillLoader.SkillMetadata> metadata = loader.loadMetadata();
System.out.println("=== 可用的Skills ===");
metadata.forEach((name, meta) ->
System.out.println("- " + name + ": " + meta.getDescription())
);
} catch (IOException e) {
System.err.println("加载Skills失败: " + e.getMessage());
}
}
/**
* 启动交互式命令行界面
*/
public void run() {
// 显示可用Skills
showAvailableSkills();
System.out.println("\n输入你的请求(输入 'exit' 或 'quit' 退出):");
// 交互式对话循环
while (true) {
System.out.print("\n你的请求: ");
String userInput = scanner.nextLine().trim();
if (userInput.equalsIgnoreCase("exit") ||
userInput.equalsIgnoreCase("quit")) {
break;
}
if (userInput.isEmpty()) {
continue;
}
String response = process(userInput);
System.out.println("\nClaude: " + response);
}
System.out.println("再见!");
scanner.close();
}
public static void main(String[] args) {
String skillsDir = args.length > 0 ? args[0] : "skills";
MySkills mySkills = new MySkills(skillsDir);
mySkills.run();
}
}pom.xml - Maven配置
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0
http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.claude</groupId>
<artifactId>myskills</artifactId>
<version>1.0.0</version>
<properties>
<maven.compiler.source>17</maven.compiler.source>
<maven.compiler.target>17</maven.compiler.target>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<!-- 如果需要集成HTTP客户端调用Claude API -->
<dependency>
<groupId>com.squareup.okhttp3</groupId>
<artifactId>okhttp</artifactId>
<version>4.12.0</version>
</dependency>
<!-- JSON处理(可选) -->
<dependency>
<groupId>com.google.code.gson</groupId>
<artifactId>gson</artifactId>
<version>2.10.1</version>
</dependency>
<!-- 单元测试 -->
<dependency>
<groupId>org.junit.jupiter</groupId>
<artifactId>junit-jupiter</artifactId>
<version>5.10.1</version>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<version>3.11.0</version>
</plugin>
</plugins>
</build>
</project>示例Skill
skills/ai-article/SKILL.md
# AI技术文章生成器
## 描述
按照二哥风格撰写AI技术类文章,字数2000-3000字,语气通俗易懂
## 触发条件
- 用户提到"AI文章"、"技术文章"
- 包含"写一篇"、"创作"等关键词
- 涉及AI工具、大模型、编程工具等话题
## 工作流程
1. 确认当前日期
2. 搜集相关资料
3. 生成文章大纲
4. 按照二哥风格撰写文章
5. 检查质量
## 输出格式
---
title: 文章标题
shortTitle: 短标题
description: 文章描述
tag:
- AI
- 技术文章
category:
- 技术文章
author: 二哥
date: YYYY-MM-DD
---
正文内容...运行效果
# 编译项目
# 运行程序
MySkills
=== 可用的Skills ===
- ai-article: 按照二哥风格撰写AI技术类文章
- git-commit: 创建符合规范的Git提交信息
输入你的请求(输入 'exit' 或 'quit' 退出):
你的请求: 帮我写一篇关于Claude Skills的AI文章
Claude: 【使用Skill: ai-article】
# AI技术文章生成器
## 描述
按照二哥风格撰写AI技术类文章,字数2000-3000字,语气通俗易懂
[完整Skill内容...]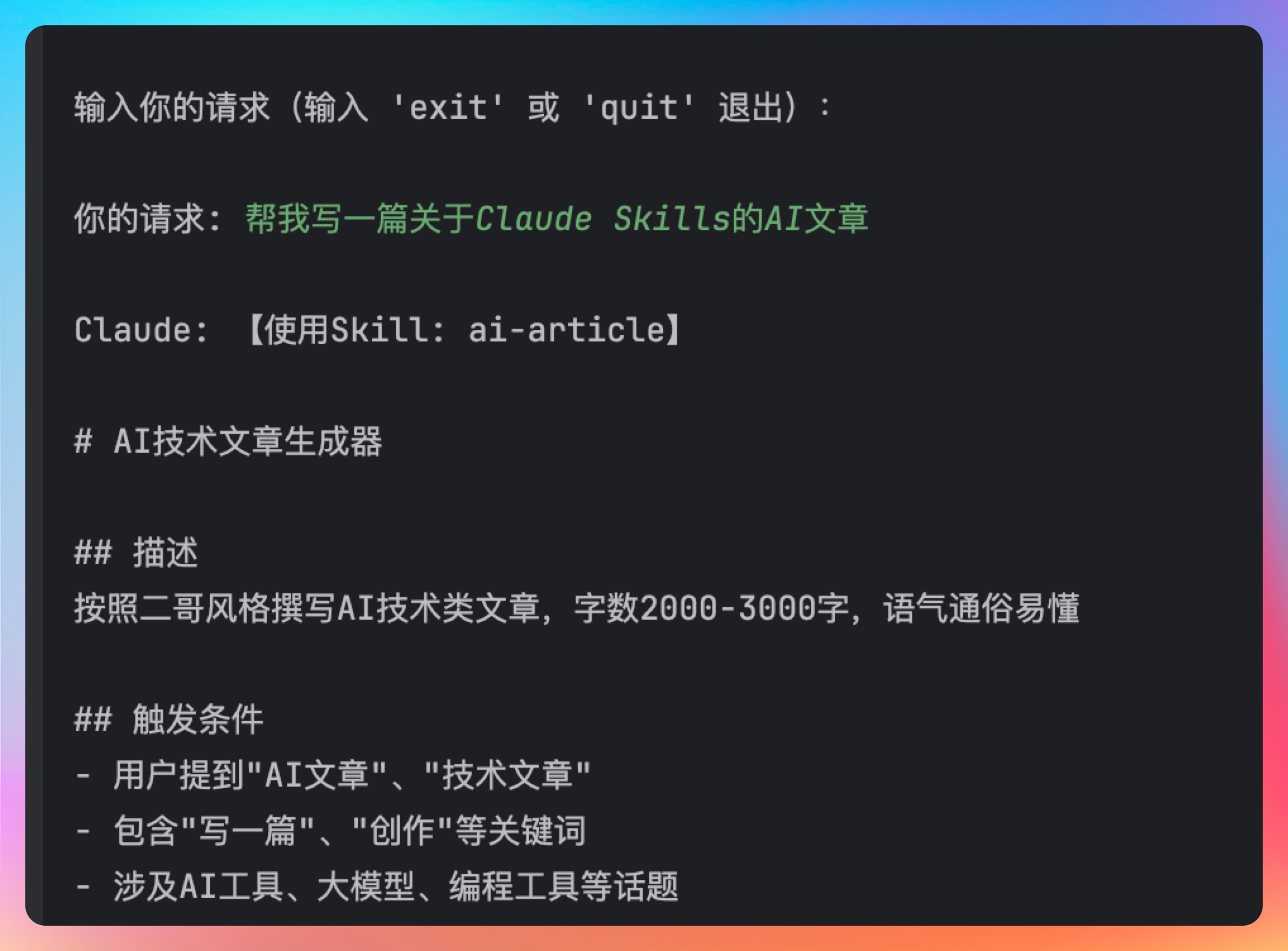
与真实Claude Skills的差距
这个简化版本展示了核心思路,但和真实的Claude Skills还有差距:
- 匹配算法:我们用的是简单关键词匹配,Claude用的是语义理解
- LLM集成:真实版本会调用Claude API,将Skill内容注入system prompt
- 工具支持:真实版本支持Skill调用外部工具(如搜索、文件操作)
- 上下文管理:真实版本会管理上下文窗口,避免超出限制
如果要做到生产级别,你需要:
- 集成Anthropic API(GLM-4.7也行)
- 使用向量数据库做语义匹配
- 实现工具调用机制
- 添加上下文管理
ending
今天我们系统地学习了Claude Skills,从核心原理到实战应用,再到自己动手实现。
核心要点回顾:
- Skills是"专业技能包",通过工作流程让AI更专业
- 渐进式披露机制解决了token浪费问题
- Skills和MCP互补,不是替代关系
- 写好Skill的关键是清晰的流程和明确的输出格式
- TRAE等AI IDE都已支持Skills功能
Skills的出现,让AI从"通用助手"向"领域专家"迈进了一步。这不就是Agent的雏形吗?
下一步行动建议:
- 尝试在Claude Code中使用官方Skills
- 写一个符合自己工作流的Skill
- 如果感兴趣,可以实现一个完整的Skills系统
好了,今天就到这里。如果你觉得有收获,别忘了点赞关注哦!
参考资料: