Java 9为什么要将String的底层实现由char数组改成了byte数组?
“二哥,最近在我阅读 Java 11 的字符串源码,发现和 Java 8 的有很大不同。”三妹的脸上洋溢着青春的微笑😊,甜美地说道:“String 类的源码已经由 char[] 优化为了 byte[] 来存储字符串内容,为什么要这样做呢?”
“开门见山地说,从 char[] 到 byte[],最主要的目的是节省字符串占用的内存空间。内存占用减少带来的另外一个好处,就是 GC 次数也会减少。”我用右手的大拇指凑了一下眼镜解释道。
为什么要优化?
我们使用 jmap -histo:live pid | head -n 10 命令就可以查看到堆内对象示例的统计信息、查看 ClassLoader 的信息以及 finalizer 队列。
以我正在运行着的编程喵项目实例(基于 Java 8)来说,结果是这样的。
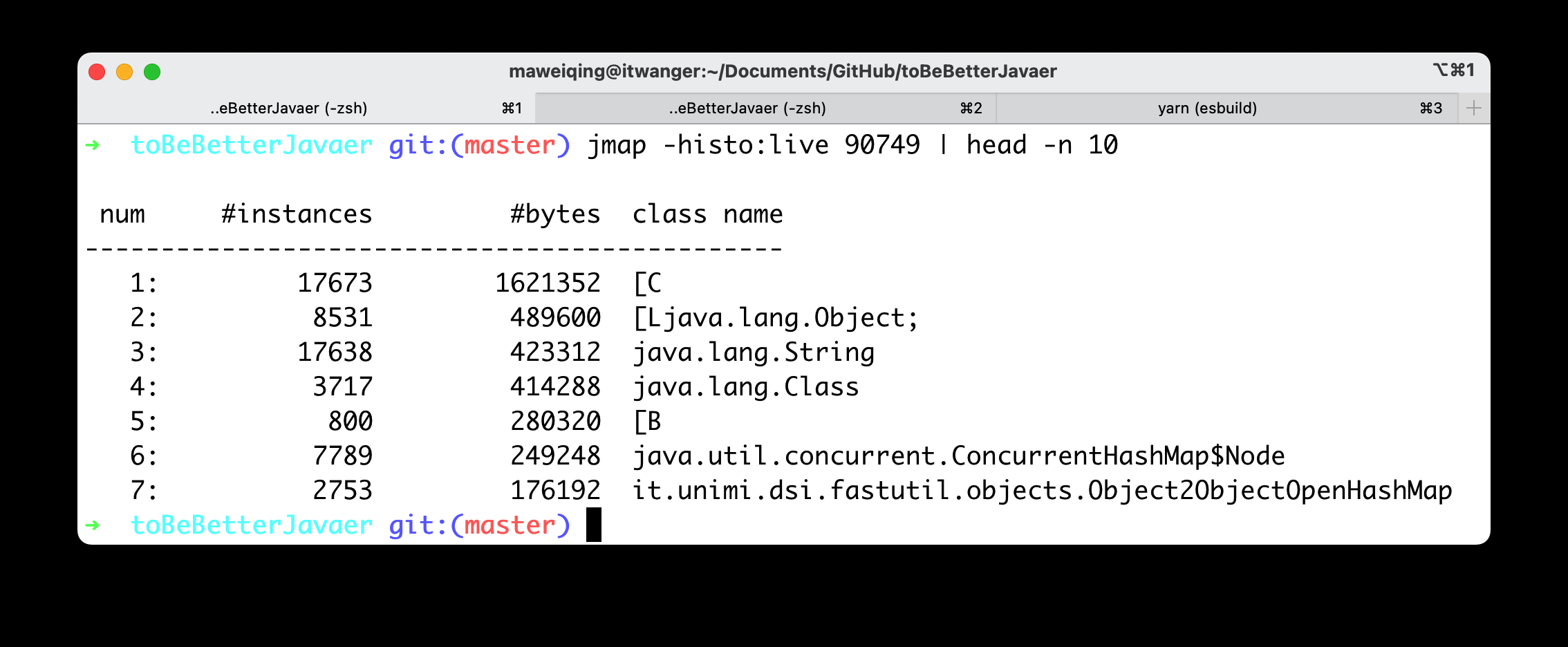
其中 String 对象有 17638 个,占用了 423312 个字节的内存,排在第三位。
由于 Java 8 的 String 内部实现仍然是 char[],所以我们可以看到内存占用排在第 1 位的就是 char 数组。
char[] 对象有 17673 个,占用了 1621352 个字节的内存,排在第一位。
那也就是说优化 String 节省内存空间是非常有必要的,如果是去优化一个使用频率没有 String 这么高的类,就没什么必要,对吧?
为什么能节省内存空间?
众所周知,char 类型的数据在 JVM 中是占用两个字节的,并且使用的是 UTF-8 编码,其值范围在 '\u0000'(0)和 '\uffff'(65,535)(包含)之间。
也就是说,使用 char[] 来表示 String 就会导致,即使 String 中的字符只用一个字节就能表示,也得占用两个字节。
PS:在计算机中,单字节字符通常指的是一个字节(8位)可以表示的字符,而双字节字符则指需要两个字节(16位)才能表示的字符。单字节字符和双字节字符的定义是相对的,不同的编码方式对应的单字节和双字节字符集也不同。常见的单字节字符集有ASCII(美国信息交换标准代码)、ISO-8859(国际标准化组织标准编号8859)、GBK(汉字内码扩展规范)、GB2312(中国国家标准,现在已经被GBK取代),像拉丁字母、数字、标点符号、控制字符都是单字节字符。双字节字符集包括 Unicode、UTF-8、GB18030(中国国家标准),中文、日文、韩文、拉丁文扩展字符属于双字节字符。
当然了,仅仅将 char[] 优化为 byte[] 是不够的,还要配合 Latin-1 的编码方式,该编码方式是用单个字节来表示字符的,这样就比 UTF-8 编码节省了更多的空间。
换句话说,对于:
String name = "jack";这样的,使用 Latin-1 编码,占用 4 个字节就够了。
但对于:
String name = "小二";这种,木的办法,只能使用 UTF16 来编码。
针对 JDK 9 的 String 源码里,为了区别编码方式,追加了一个 coder 字段来区分。
/**
* The identifier of the encoding used to encode the bytes in
* {@code value}. The supported values in this implementation are
*
* LATIN1
* UTF16
*
* @implNote This field is trusted by the VM, and is a subject to
* constant folding if String instance is constant. Overwriting this
* field after construction will cause problems.
*/
private final byte coder;Java 会根据字符串的内容自动设置为相应的编码,要么 Latin-1 要么 UTF16。
也就是说,从 char[] 到 byte[],中文是两个字节,纯英文是一个字节,在此之前呢,中文是两个字节,英文也是两个字节。
为什么用UTF-16而不用UTF-8呢?
在 UTF-8 中,0-127 号的字符用 1 个字节来表示,使用和 ASCII 相同的编码。只有 128 号及以上的字符才用 2 个、3 个或者 4 个字节来表示。
- 如果只有一个字节,那么最高的比特位为 0;
- 如果有多个字节,那么第一个字节从最高位开始,连续有几个比特位的值为 1,就使用几个字节编码,剩下的字节均以 10 开头。
具体的表现形式为:
- 0xxxxxxx:一个字节;
- 110xxxxx 10xxxxxx:两个字节编码形式(开始两个 1);
- 1110xxxx 10xxxxxx 10xxxxxx:三字节编码形式(开始三个 1);
- 11110xxx 10xxxxxx 10xxxxxx 10xxxxxx:四字节编码形式(开始四个 1)。
也就是说,UTF-8 是变长的,那对于 String 这种有随机访问方法的类来说,就很不方便。所谓的随机访问,就是charAt、subString这种方法,随便指定一个数字,String要能给出结果。如果字符串中的每个字符占用的内存是不定长的,那么进行随机访问的时候,就需要从头开始数每个字符的长度,才能找到你想要的字符。
那三妹可能会问,UTF-16也是变长的呢?一个字符还可能占用 4 个字节呢?
的确,UTF-16 使用 2 个或者 4 个字节来存储字符。
- 对于 Unicode 编号范围在 0 ~ FFFF 之间的字符,UTF-16 使用两个字节存储。
- 对于 Unicode 编号范围在 10000 ~ 10FFFF 之间的字符,UTF-16 使用四个字节存储,具体来说就是:将字符编号的所有比特位分成两部分,较高的一些比特位用一个值介于 D800~DBFF 之间的双字节存储,较低的一些比特位(剩下的比特位)用一个值介于 DC00~DFFF 之间的双字节存储。
但是在 Java 中,一个字符(char)就是 2 个字节,占 4 个字节的字符,在 Java 里也是用两个 char 来存储的,而String的各种操作,都是以Java的字符(char)为单位的,charAt是取得第几个char,subString取的也是第几个到第几个char组成的子串,甚至length返回的都是char的个数。
所以UTF-16在Java的世界里,就可以视为一个定长的编码。
“好了,三妹,那关于Java 9为什么要将String的底层实现由char数组改成了byte数组就聊到这里吧。”我对三妹说,“有时候,读一读源码确实能成长很多,多问问为什么,挺好!”
“是啊,任何知识想要深入去学习,就能挖掘出来很多。”三妹说,“比如说今天聊到的UTF-16和UTF-8。”
“好了,我要去回答星球球友的提问了,你可以休息会,比如说听听 H.O.T 的歌,真不错。”
“哈哈,没想到,哥你也是个 H.O.T 的粉丝啊!”
GitHub 上标星 10000+ 的开源知识库《二哥的 Java 进阶之路》第一版 PDF 终于来了!包括Java基础语法、数组&字符串、OOP、集合框架、Java IO、异常处理、Java 新特性、网络编程、NIO、并发编程、JVM等等,共计 32 万余字,500+张手绘图,可以说是通俗易懂、风趣幽默……详情戳:太赞了,GitHub 上标星 10000+ 的 Java 教程
微信搜 沉默王二 或扫描下方二维码关注二哥的原创公众号沉默王二,回复 222 即可免费领取。
